Sentiment Analysis with Logistic Regression
This gives a simple example of explaining a linear logistic regression sentiment analysis model using shap. Note that with a linear model, the SHAP value of feature \(i\) for the prediction \(f(x)\) (assuming feature independence) is just \(\phi_i = \beta_i \cdot (x_i - E[x_i])\). Since we are explaining a logistic regression model, the units of the SHAP values will be in the log-odds space.
The dataset we are using is the classic IMDB dataset from this paper. When explaining the model, it is interesting to observe how the words that are absent from the text are sometimes just as important as those that are present.
[1]:
import numpy as np
import sklearn
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
import shap
np.random.seed(101)
shap.initjs()

Load the IMDB dataset
[2]:
corpus, y = shap.datasets.imdb()
corpus_train, corpus_test, y_train, y_test = train_test_split(corpus, y, test_size=0.2, random_state=7)
vectorizer = TfidfVectorizer(min_df=10)
X_train = vectorizer.fit_transform(
corpus_train
).toarray() # sparse also works but Explanation slicing is not yet supported
X_test = vectorizer.transform(corpus_test).toarray()
Fit a linear logistic regression model
[3]:
model = sklearn.linear_model.LogisticRegression(penalty="l2", C=0.1)
model.fit(X_train, y_train)
print(classification_report(y_test, model.predict(X_test)))
precision recall f1-score support
False 0.84 0.84 0.84 2426
True 0.85 0.85 0.85 2574
accuracy 0.85 5000
macro avg 0.85 0.85 0.85 5000
weighted avg 0.85 0.85 0.85 5000
Explain the linear model
[4]:
explainer = shap.Explainer(model, X_train, feature_names=vectorizer.get_feature_names_out())
shap_values = explainer(X_test)
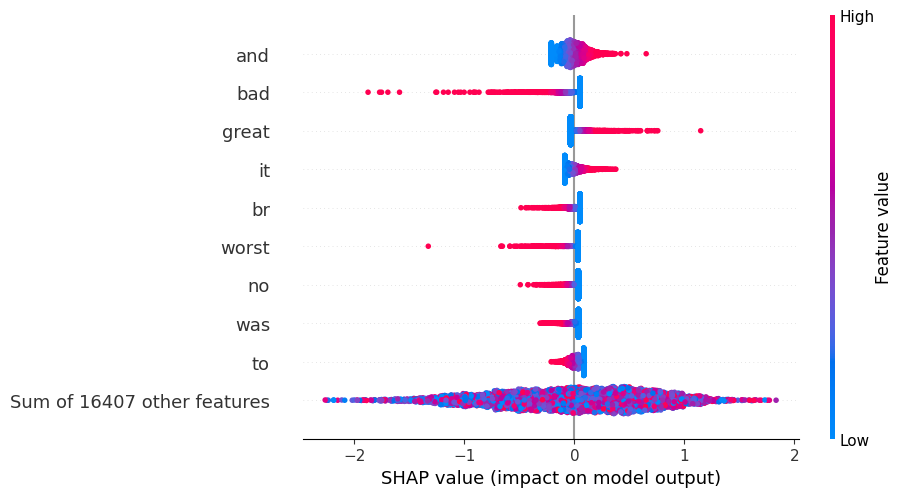
Summarize the effect of all the features
[5]:
shap.plots.beeswarm(shap_values)
No data for colormapping provided via 'c'. Parameters 'vmin', 'vmax' will be ignored
Explain the first review’s sentiment prediction
Remember that higher SHAP values means the review is more likely to be negative. So in the plots below, the “red” features are increasing the chance of a positive review, while the “blue” features are lowering the chance. It is interesting to see how what is not present in the text (like bad=0 below) is often just as important as what is in the text. Note that the values of the features are TF-IDF values.
[6]:
ind = 0
shap.plots.force(shap_values[ind])
[6]:
Have you run `initjs()` in this notebook? If this notebook was from another user you must also trust this notebook (File -> Trust notebook). If you are viewing this notebook on github the Javascript has been stripped for security. If you are using JupyterLab this error is because a JupyterLab extension has not yet been written.
[7]:
print("Positive" if y_test[ind] else "Negative", "Review:")
print(corpus_test[ind])
Positive Review:
"Twelve Monkeys" is odd and disturbing, yet being so clever and intelligent at the same time. It cleverly jumps between future and the past, and the story it tells is about a man named James Cole, a convict, who is sent back to the past to gather information about a man-made virus that wiped out 5 billion of the human population on the planet back in 1996. At first Cole is sent back to the year 1990 by accident and by misfortune he is taken to a mental institution where he tries to explain his purpose and where he meets a psychiatrist Dr. Kathryn Railly who tries to help him and a patient named Jeffrey Goines, the insane son of a famous scientist. Being provocative and somehow so sensible, dealing with and between reason and madness, the movie is a definite masterpiece in the history of science-fiction films.<br /><br />The story is just fantastic. It's so original and so entertaining. The screenplay itself written by David and Janet Peoples is inspired by a movie named "La Jetée" (1962) which I haven't seen, but I must thank the director and writer of the movie, Chris Marker, for giving such an inspiration for the writers of "Twelve Monkeys". I read a little about "La Jetée", it's not the same story but it has the same idea, so this is not just a copy of it. David and Janet Peoples have transformed this great deal of inspiration to a modernized story, which tells about this urgent need for people to find a solution for maintaining human existence and it does it in a so beautiful and a realistic way that it's a guaranteed thrill ride from the beginning till the end. The music used in the film is odd and somehow so funny and amusing it doesn't really fit until you really get it and when you do you realise that it's so compelling, composed by Paul Buckmaster.<br /><br />Terry Gilliam, who we remember from Monty Python, as the director of the movie was a real surprise for me, as I really never thought him as a director type of a person. I know he has directed movies before, but I really couldn't believe that he could make something this magnificent. It shouldn't be a surprise though, as he does an amazing job. You can still sense that same weirdness as in the Python's, but for me the directing is pretty much flawless though in its odd way of describing things it also makes some scenes strangely disturbing. Yes, it is indeed odd, weird, bizarre and disturbing, so it also makes the movie a bit heavy too, so the weak minded viewers will probably find it hard to watch the movie all the way through. It's not as heavy as you could imagine, but it just has these certain things which in their own purpose are sometimes pretty severe to watch. Despite that, the movie holds this pure intelligence inside it and through flashbacks, dreams, jumps between the past and the future it mixes up the whole story in a very clever way and it doesn't even make the plot messy in any part, though it does need concentration from the viewer after all.<br /><br />What comes to acting, well the movie doesn't even go wrong there. The role of James Cole is played by the mighty Bruce Willis, who probably does his best role performance yet to date. Now people may disagree with me, as he did some fine job in for example "The Sixth Sense" as well, but for me the role of James Cole was so ideal for Willis and he performs it incredibly well. The character is very well written too, yet performed even better. Cole starts to question his own existence and he deals with himself, starting to question his actual time of living, trying to survive and find the crucial missing piece of the puzzle. By hardship he starts to loose his faith, questioning if he can even trust or believe himself. Other role performances worth mentioning are the performances of Madeleine Stow and Brad Pitt. Stow plays the role of Kathryn Railly, the psychiatrist of James Cole, who sees something strangely familiar in Cole and decides to help him to deal with his madness. She somehow starts to believe Cole's story but as a believer of science she tries to find solutions through it and tries to deal with reason when it comes to unbelievable things. Brad Pitt is so good in the role of Jeffrey Goines and he also does one of his best role performances yet to date. The insane yet hilarious personality of the character brought Pitt even an Oscar nomination for it, so I guess I'm not praising the honestly fabulous performance for nothing.<br /><br />All in all, "Twelve Monkeys" is a great science-fiction experience and it will surely be a recommendation for everyone, especially for the sci-fi fans. It includes brilliant characters and superb role performances, especially from Willis and Pitt, and an original and an entertaining story which forms a plot that's so intelligent and clever. Yet being that already mentioned weird and disturbing it definitely captures the viewer's attention by making it interesting and witty. It's also an explosive thriller and it has romance in it too, so it's all that in same package and that makes it one of the best sci-fi motion pictures I've ever seen. Through the odd yet terrific vision of Terry Gilliam it manages to keep itself in balance despite the somewhat bumpy yet somehow stable ride. Hard to explain really, but that's how it is, it's mind blowing.
Explain the second review’s sentiment prediction
[8]:
ind = 1
shap.plots.force(shap_values[ind])
[8]:
Have you run `initjs()` in this notebook? If this notebook was from another user you must also trust this notebook (File -> Trust notebook). If you are viewing this notebook on github the Javascript has been stripped for security. If you are using JupyterLab this error is because a JupyterLab extension has not yet been written.
[9]:
print("Positive" if y_test[ind] else "Negative", "Review:")
print(corpus_test[ind])
Negative Review:
I don't understand the positive comments made about this film. It is cheap and nasty on all levels and I cannot understand how it ever got made.<br /><br />Cartoon characters abound - Sue's foul-mouthed, alcoholic, layabout, Irish father being a prime example. None of the characters are remotely sympathetic - except, briefly, for Sue's Asian boyfriend but even he then turns out to be capable of domestic violence! As desperately unattractive as they both are, I've no idea why either Rita and/or Sue would throw themselves at a consummate creep like Bob - but given that they do, why should I be expected to care what happens to them? So many reviews keep carping on about how "realistic" it is. If that is true, it is a sad reflection on society but no reason to put it on film.<br /><br />I didn't like the film at all.
Explain the third review’s sentiment prediction
[10]:
ind = 2
shap.plots.force(shap_values[ind])
[10]:
Have you run `initjs()` in this notebook? If this notebook was from another user you must also trust this notebook (File -> Trust notebook). If you are viewing this notebook on github the Javascript has been stripped for security. If you are using JupyterLab this error is because a JupyterLab extension has not yet been written.
[11]:
print("Positive" if y_test[ind] else "Negative", "Review:")
print(corpus_test[ind])
Positive Review:
I finally saw this film tonight after renting it at Blockbuster (VHS). I have to agree that it is wildly original. Yes, maybe the characters were not fully realized but it isn't one of those movies. Rather, we are treated to the director's eye, his vision of what the story is about. And it does not stop. And to be honest, I didn't want it to. I do believe that Sabu had to have influenced the director's of 'Lock, Stock & Two Smoking Barrels' and 'Run, Lola, Run'. But I absolutely loved the way the three leads SEE the beautiful woman on the street to distract them momentarily. I really need to see this director's other work because this film really intrigued me. If you want insight, culture, sturm und drang, go somewhere else. If you want a laugh, camera movement and criminal hilarity, look here.