This notebook demonstrates how to get explanations for the output of gpt2 used for open ended text generation. In this demo, we use the pretrained gpt2 model provided by hugging face (https://huggingface.co/gpt2) to explain the generated text by gpt2. We further showcase how to get explanations for custom output generated text and plot global input token importances for any output generated token.
Below, we set certain model configurations. We need to define if the model is a decoder or encoder-decoder. This can be set through the ‘is_decoder’ or ‘is_encoder_decoder’ param in model’s config file. We can also set custom model generation parameters which will be used during the output text generation decoding process.
[3]:
# set model decoder to truemodel.config.is_decoder=True# set text-generation params under task_specific_paramsmodel.config.task_specific_params["text-generation"]={"do_sample":True,"max_length":50,"temperature":0.7,"top_k":50,"no_repeat_ngram_size":2,}
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
[9]:
shap.plots.text(shap_values)
[0]
outputs
in
the
coming
days
.
inputs
0.442
Scientists
-0.035
confirmed
-0.168
the
0.24
worst
-0.156
possible
0.075
outcome
-0.365
:
-0.385
the
0.093
massive
0.221
asteroid
-0.166
will
1.28
collide
0.489
with
1.436
Earth
inputs
0.442
Scientists
-0.035
confirmed
-0.168
the
0.24
worst
-0.156
possible
0.075
outcome
-0.365
:
-0.385
the
0.093
massive
0.221
asteroid
-0.166
will
1.28
collide
0.489
with
1.436
Earth
inputs
-0.26
Scientists
-0.074
confirmed
0.251
the
-0.062
worst
0.065
possible
-0.117
outcome
-0.009
:
0.308
the
-0.011
massive
-0.203
asteroid
-0.308
will
0.252
collide
0.291
with
-0.145
Earth
inputs
-0.26
Scientists
-0.074
confirmed
0.251
the
-0.062
worst
0.065
possible
-0.117
outcome
-0.009
:
0.308
the
-0.011
massive
-0.203
asteroid
-0.308
will
0.252
collide
0.291
with
-0.145
Earth
inputs
0.325
Scientists
0.202
confirmed
0.054
the
-0.493
worst
0.407
possible
0.318
outcome
-0.351
:
-0.077
the
-0.146
massive
0.207
asteroid
2.257
will
2.382
collide
-0.043
with
0.427
Earth
inputs
0.325
Scientists
0.202
confirmed
0.054
the
-0.493
worst
0.407
possible
0.318
outcome
-0.351
:
-0.077
the
-0.146
massive
0.207
asteroid
2.257
will
2.382
collide
-0.043
with
0.427
Earth
inputs
0.001
Scientists
0.446
confirmed
0.128
the
-0.074
worst
0.107
possible
-0.122
outcome
-0.015
:
-0.098
the
0.06
massive
0.12
asteroid
0.123
will
0.337
collide
0.06
with
-0.411
Earth
inputs
0.001
Scientists
0.446
confirmed
0.128
the
-0.074
worst
0.107
possible
-0.122
outcome
-0.015
:
-0.098
the
0.06
massive
0.12
asteroid
0.123
will
0.337
collide
0.06
with
-0.411
Earth
inputs
-0.578
Scientists
0.36
confirmed
0.012
the
0.043
worst
-0.247
possible
-0.11
outcome
-0.245
:
0.284
the
0.032
massive
0.062
asteroid
-0.973
will
1.145
collide
0.796
with
0.217
Earth
inputs
-0.578
Scientists
0.36
confirmed
0.012
the
0.043
worst
-0.247
possible
-0.11
outcome
-0.245
:
0.284
the
0.032
massive
0.062
asteroid
-0.973
will
1.145
collide
0.796
with
0.217
Earth
inputs
0.016
Scientists
0.292
confirmed
0.12
the
0.172
worst
0.169
possible
0.194
outcome
-0.078
:
0.215
the
0.122
massive
0.089
asteroid
-0.078
will
0.122
collide
0.168
with
-0.109
Earth
inputs
0.016
Scientists
0.292
confirmed
0.12
the
0.172
worst
0.169
possible
0.194
outcome
-0.078
:
0.215
the
0.122
massive
0.089
asteroid
-0.078
will
0.122
collide
0.168
with
-0.109
Earth
Custom text generation and debugging biased outputs
Below we demonstrate the process of how to explain the liklihood of generating a particular output sentence given an input sentence using the model. For example, we ask a question: Which country’s inhabitant (target) in the sentence “I know many people who are [target].” would have a high liklilhood of generating the token “vodka” in the output sentence “They love their vodka!” ? For this, we first define input-output sentence pairs
[10]:
# define inputx=["I know many people who are Russian.","I know many people who are Greek.","I know many people who are Australian.","I know many people who are American.","I know many people who are Italian.","I know many people who are Spanish.","I know many people who are German.","I know many people who are Indian.",]
[11]:
# define outputy=["They love their vodka!","They love their vodka!","They love their vodka!","They love their vodka!","They love their vodka!","They love their vodka!","They love their vodka!","They love their vodka!",]
We wrap the model with a Teacher Forcing scoring class and create a Text masker
Now that we have generated the SHAP values, we can have a look at the contribution of tokens in the input driving the token “vodka” in the output sentence using the text plot. Note: The red color indicates a positive contribution while the blue color indicates negative contribution and the intensity of the color shows its strength in the respective direction.
[15]:
shap.plots.text(shap_values)
[0]
outputs
They
love
their
vodka
!
inputs
-0.377
I
-0.158
know
-0.157
many
0.124
people
0.035
who
0.109
are
-0.488
Russian
0.375
.
inputs
-0.377
I
-0.158
know
-0.157
many
0.124
people
0.035
who
0.109
are
-0.488
Russian
0.375
.
inputs
0.126
I
0.448
know
0.248
many
0.45
people
0.032
who
0.061
are
-0.089
Russian
-0.082
.
inputs
0.126
I
0.448
know
0.248
many
0.45
people
0.032
who
0.061
are
-0.089
Russian
-0.082
.
inputs
-0.069
I
0.088
know
0.297
many
0.144
people
0.175
who
0.253
are
-0.024
Russian
-0.087
.
inputs
-0.069
I
0.088
know
0.297
many
0.144
people
0.175
who
0.253
are
-0.024
Russian
-0.087
.
inputs
0.036
I
-0.013
know
-0.132
many
0.021
people
-0.062
who
-0.164
are
2.648
Russian
0.05
.
inputs
0.036
I
-0.013
know
-0.132
many
0.021
people
-0.062
who
-0.164
are
2.648
Russian
0.05
.
inputs
-0.449
I
-0.182
know
-0.125
many
-0.309
people
-0.122
who
-0.071
are
0.183
Russian
0.202
.
inputs
-0.449
I
-0.182
know
-0.125
many
-0.309
people
-0.122
who
-0.071
are
0.183
Russian
0.202
.
[1]
outputs
They
love
their
vodka
!
inputs
-0.351
I
-0.125
know
-0.242
many
0.149
people
0.054
who
0.144
are
-0.716
Greek
0.387
.
inputs
-0.351
I
-0.125
know
-0.242
many
0.149
people
0.054
who
0.144
are
-0.716
Greek
0.387
.
inputs
0.192
I
0.511
know
0.229
many
0.516
people
-0.004
who
-0.029
are
0.407
Greek
-0.088
.
inputs
0.192
I
0.511
know
0.229
many
0.516
people
-0.004
who
-0.029
are
0.407
Greek
-0.088
.
inputs
-0.044
I
0.076
know
0.277
many
0.147
people
0.169
who
0.339
are
0.141
Greek
-0.106
.
inputs
-0.044
I
0.076
know
0.277
many
0.147
people
0.169
who
0.339
are
0.141
Greek
-0.106
.
inputs
0.011
I
0.001
know
-0.311
many
0.031
people
-0.15
who
-0.445
are
0.162
Greek
0.061
.
inputs
0.011
I
0.001
know
-0.311
many
0.031
people
-0.15
who
-0.445
are
0.162
Greek
0.061
.
inputs
-0.445
I
-0.14
know
-0.125
many
-0.218
people
-0.131
who
-0.041
are
0.339
Greek
0.241
.
inputs
-0.445
I
-0.14
know
-0.125
many
-0.218
people
-0.131
who
-0.041
are
0.339
Greek
0.241
.
[2]
outputs
They
love
their
vodka
!
inputs
-0.41
I
-0.158
know
-0.176
many
0.144
people
-0.015
who
0.015
are
-0.529
Australian
0.701
.
inputs
-0.41
I
-0.158
know
-0.176
many
0.144
people
-0.015
who
0.015
are
-0.529
Australian
0.701
.
inputs
0.148
I
0.457
know
0.248
many
0.453
people
0.032
who
0.042
are
0.365
Australian
-0.057
.
inputs
0.148
I
0.457
know
0.248
many
0.453
people
0.032
who
0.042
are
0.365
Australian
-0.057
.
inputs
-0.031
I
0.115
know
0.32
many
0.177
people
0.184
who
0.298
are
0.089
Australian
-0.053
.
inputs
-0.031
I
0.115
know
0.32
many
0.177
people
0.184
who
0.298
are
0.089
Australian
-0.053
.
inputs
-0.14
I
-0.093
know
-0.265
many
-0.371
people
-0.11
who
-0.648
are
-0.393
Australian
0.123
.
inputs
-0.14
I
-0.093
know
-0.265
many
-0.371
people
-0.11
who
-0.648
are
-0.393
Australian
0.123
.
inputs
-0.455
I
-0.201
know
-0.14
many
-0.315
people
-0.121
who
-0.125
are
0.119
Australian
0.227
.
inputs
-0.455
I
-0.201
know
-0.14
many
-0.315
people
-0.121
who
-0.125
are
0.119
Australian
0.227
.
[3]
outputs
They
love
their
vodka
!
inputs
-0.439
I
-0.185
know
-0.162
many
0.134
people
-0.03
who
0.03
are
-0.632
American
0.39
.
inputs
-0.439
I
-0.185
know
-0.162
many
0.134
people
-0.03
who
0.03
are
-0.632
American
0.39
.
inputs
0.13
I
0.451
know
0.174
many
0.398
people
-0.019
who
-0.072
are
0.474
American
-0.095
.
inputs
0.13
I
0.451
know
0.174
many
0.398
people
-0.019
who
-0.072
are
0.474
American
-0.095
.
inputs
-0.04
I
0.109
know
0.343
many
0.212
people
0.18
who
0.275
are
0.372
American
-0.041
.
inputs
-0.04
I
0.109
know
0.343
many
0.212
people
0.18
who
0.275
are
0.372
American
-0.041
.
inputs
-0.094
I
-0.055
know
-0.366
many
-0.43
people
-0.082
who
-0.514
are
-0.519
American
0.027
.
inputs
-0.094
I
-0.055
know
-0.366
many
-0.43
people
-0.082
who
-0.514
are
-0.519
American
0.027
.
inputs
-0.484
I
-0.182
know
-0.129
many
-0.34
people
-0.116
who
-0.117
are
-0.212
American
0.283
.
inputs
-0.484
I
-0.182
know
-0.129
many
-0.34
people
-0.116
who
-0.117
are
-0.212
American
0.283
.
[4]
outputs
They
love
their
vodka
!
inputs
-0.454
I
-0.149
know
-0.24
many
0.106
people
0.079
who
0.155
are
-0.76
Italian
0.428
.
inputs
-0.454
I
-0.149
know
-0.24
many
0.106
people
0.079
who
0.155
are
-0.76
Italian
0.428
.
inputs
0.138
I
0.485
know
0.258
many
0.472
people
-0.004
who
0.056
are
0.561
Italian
-0.141
.
inputs
0.138
I
0.485
know
0.258
many
0.472
people
-0.004
who
0.056
are
0.561
Italian
-0.141
.
inputs
-0.056
I
0.119
know
0.3
many
0.192
people
0.172
who
0.285
are
0.163
Italian
-0.124
.
inputs
-0.056
I
0.119
know
0.3
many
0.192
people
0.172
who
0.285
are
0.163
Italian
-0.124
.
inputs
-0.012
I
-0.115
know
-0.23
many
-0.142
people
-0.084
who
-0.444
are
0.779
Italian
0.203
.
inputs
-0.012
I
-0.115
know
-0.23
many
-0.142
people
-0.084
who
-0.444
are
0.779
Italian
0.203
.
inputs
-0.467
I
-0.172
know
-0.11
many
-0.266
people
-0.12
who
-0.054
are
0.41
Italian
0.248
.
inputs
-0.467
I
-0.172
know
-0.11
many
-0.266
people
-0.12
who
-0.054
are
0.41
Italian
0.248
.
[5]
outputs
They
love
their
vodka
!
inputs
-0.399
I
-0.15
know
-0.225
many
0.106
people
0.156
who
0.288
are
-1.015
Spanish
0.414
.
inputs
-0.399
I
-0.15
know
-0.225
many
0.106
people
0.156
who
0.288
are
-1.015
Spanish
0.414
.
inputs
0.149
I
0.526
know
0.225
many
0.427
people
-0.003
who
-0.01
are
0.353
Spanish
-0.117
.
inputs
0.149
I
0.526
know
0.225
many
0.427
people
-0.003
who
-0.01
are
0.353
Spanish
-0.117
.
inputs
-0.06
I
0.101
know
0.297
many
0.157
people
0.172
who
0.327
are
0.01
Spanish
-0.081
.
inputs
-0.06
I
0.101
know
0.297
many
0.157
people
0.172
who
0.327
are
0.01
Spanish
-0.081
.
inputs
-0.048
I
-0.099
know
-0.258
many
-0.167
people
-0.103
who
-0.376
are
-0.028
Spanish
0.129
.
inputs
-0.048
I
-0.099
know
-0.258
many
-0.167
people
-0.103
who
-0.376
are
-0.028
Spanish
0.129
.
inputs
-0.482
I
-0.176
know
-0.1
many
-0.276
people
-0.129
who
-0.04
are
0.221
Spanish
0.23
.
inputs
-0.482
I
-0.176
know
-0.1
many
-0.276
people
-0.129
who
-0.04
are
0.221
Spanish
0.23
.
[6]
outputs
They
love
their
vodka
!
inputs
-0.38
I
-0.125
know
-0.282
many
0.138
people
0.063
who
0.186
are
-0.811
German
0.46
.
inputs
-0.38
I
-0.125
know
-0.282
many
0.138
people
0.063
who
0.186
are
-0.811
German
0.46
.
inputs
0.135
I
0.482
know
0.231
many
0.44
people
0.026
who
0.054
are
0.113
German
-0.122
.
inputs
0.135
I
0.482
know
0.231
many
0.44
people
0.026
who
0.054
are
0.113
German
-0.122
.
inputs
-0.059
I
0.133
know
0.317
many
0.205
people
0.201
who
0.294
are
0.229
German
-0.08
.
inputs
-0.059
I
0.133
know
0.317
many
0.205
people
0.201
who
0.294
are
0.229
German
-0.08
.
inputs
-0.079
I
-0.071
know
-0.269
many
-0.182
people
-0.065
who
-0.401
are
0.726
German
0.157
.
inputs
-0.079
I
-0.071
know
-0.269
many
-0.182
people
-0.065
who
-0.401
are
0.726
German
0.157
.
inputs
-0.461
I
-0.171
know
-0.117
many
-0.293
people
-0.135
who
-0.06
are
0.329
German
0.22
.
inputs
-0.461
I
-0.171
know
-0.117
many
-0.293
people
-0.135
who
-0.06
are
0.329
German
0.22
.
[7]
outputs
They
love
their
vodka
!
inputs
-0.484
I
-0.227
know
-0.21
many
0.128
people
-0.054
who
-0.011
are
0.1
Indian
0.374
.
inputs
-0.484
I
-0.227
know
-0.21
many
0.128
people
-0.054
who
-0.011
are
0.1
Indian
0.374
.
inputs
0.111
I
0.487
know
0.202
many
0.438
people
0.006
who
-0.076
are
0.184
Indian
-0.02
.
inputs
0.111
I
0.487
know
0.202
many
0.438
people
0.006
who
-0.076
are
0.184
Indian
-0.02
.
inputs
-0.065
I
0.104
know
0.337
many
0.176
people
0.178
who
0.277
are
0.245
Indian
-0.085
.
inputs
-0.065
I
0.104
know
0.337
many
0.176
people
0.178
who
0.277
are
0.245
Indian
-0.085
.
inputs
-0.07
I
-0.026
know
-0.341
many
-0.216
people
-0.151
who
-0.571
are
-0.666
Indian
0.175
.
inputs
-0.07
I
-0.026
know
-0.341
many
-0.216
people
-0.151
who
-0.571
are
-0.666
Indian
0.175
.
inputs
-0.429
I
-0.175
know
-0.132
many
-0.305
people
-0.088
who
-0.11
are
-0.067
Indian
0.261
.
inputs
-0.429
I
-0.175
know
-0.132
many
-0.305
people
-0.088
who
-0.11
are
-0.067
Indian
0.261
.
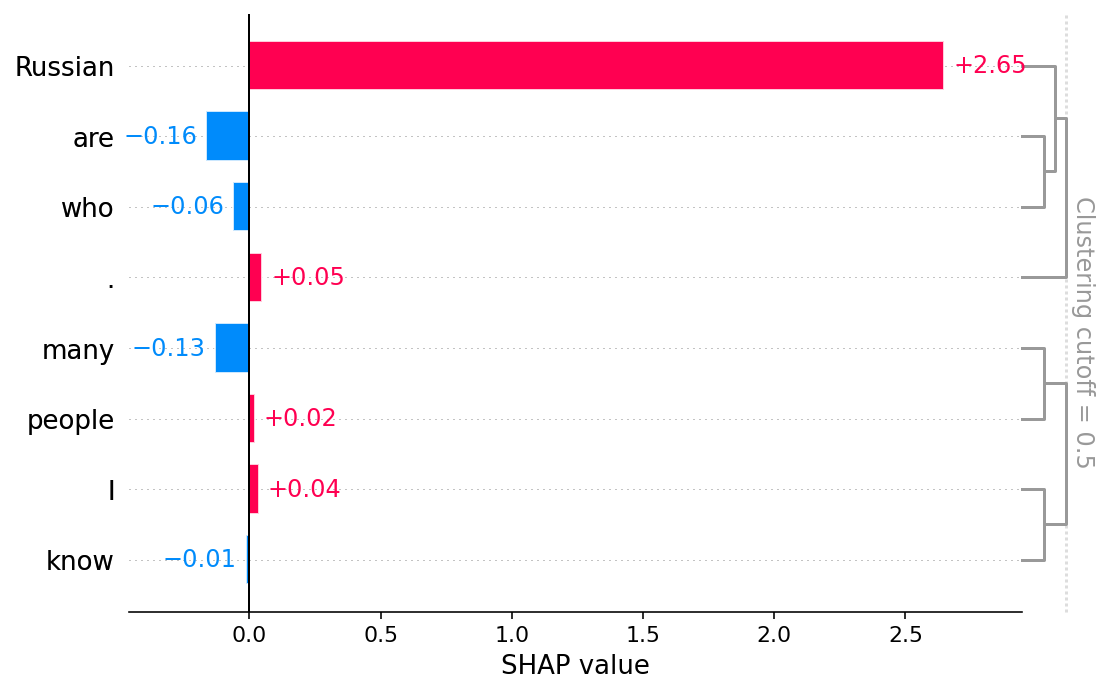
To view what input tokens impact (positively/negatively) the liklihood of generating the word “vodka”, we plot the global token importances the word “vodka”.
Voila! Russians love their vodka, dont they? :)
[16]:
shap.plots.bar(shap_values[0,:,"vodka"])
Have an idea for more helpful examples? Pull requests that add to this documentation notebook are encouraged!