Census income classification with XGBoost
This notebook demonstrates how to use XGBoost to predict the probability of an individual making over $50K a year in annual income. It uses the standard UCI Adult income dataset. To download a copy of this notebook visit github.
Gradient boosting machine methods such as XGBoost are state-of-the-art for these types of prediction problems with tabular style input data of many modalities. Tree SHAP (arXiv paper) allows for the exact computation of SHAP values for tree ensemble methods, and has been integrated directly into the C++ XGBoost code base. This allows fast exact computation of SHAP values without sampling and without providing a background dataset (since the background is inferred from the coverage of the trees).
Here we demonstrate how to use SHAP values to understand XGBoost model predictions.
[1]:
import matplotlib.pylab as pl
import numpy as np
import xgboost
from sklearn.model_selection import train_test_split
import shap
# print the JS visualization code to the notebook
shap.initjs()

Load dataset
[2]:
X, y = shap.datasets.adult()
X_display, y_display = shap.datasets.adult(display=True)
# create a train/test split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=7)
d_train = xgboost.DMatrix(X_train, label=y_train)
d_test = xgboost.DMatrix(X_test, label=y_test)
Train the model
[3]:
params = {
"eta": 0.01,
"objective": "binary:logistic",
"subsample": 0.5,
"base_score": np.mean(y_train),
"eval_metric": "logloss",
}
model = xgboost.train(
params,
d_train,
5000,
evals=[(d_test, "test")],
verbose_eval=100,
early_stopping_rounds=20,
)
[0] test-logloss:0.54663
[100] test-logloss:0.36373
[200] test-logloss:0.31793
[300] test-logloss:0.30061
[400] test-logloss:0.29207
[500] test-logloss:0.28678
[600] test-logloss:0.28381
[700] test-logloss:0.28181
[800] test-logloss:0.28064
[900] test-logloss:0.27992
[1000] test-logloss:0.27928
[1019] test-logloss:0.27935
Classic feature attributions
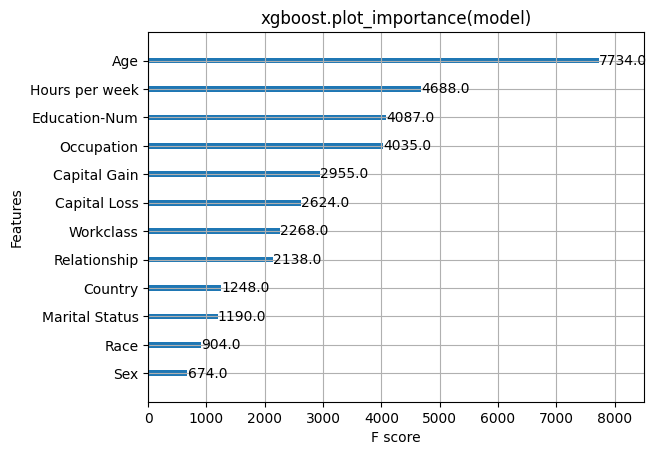
Here we try out the global feature importance calcuations that come with XGBoost. Note that they all contradict each other, which motivates the use of SHAP values since they come with consistency gaurentees (meaning they will order the features correctly).
[4]:
xgboost.plot_importance(model)
pl.title("xgboost.plot_importance(model)")
pl.show()
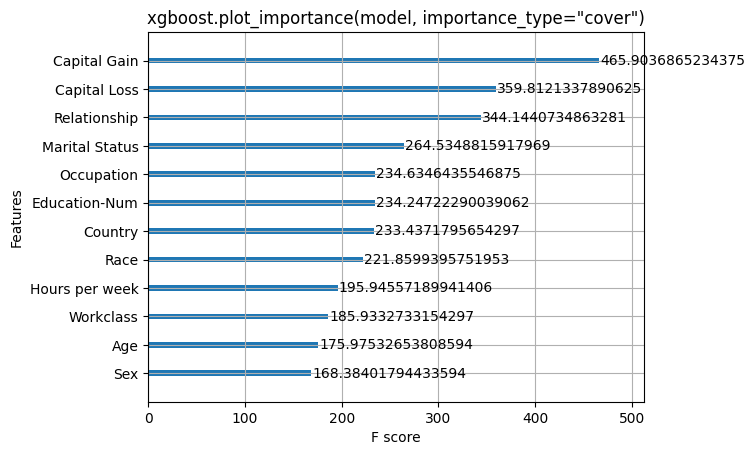
[5]:
xgboost.plot_importance(model, importance_type="cover")
pl.title('xgboost.plot_importance(model, importance_type="cover")')
pl.show()
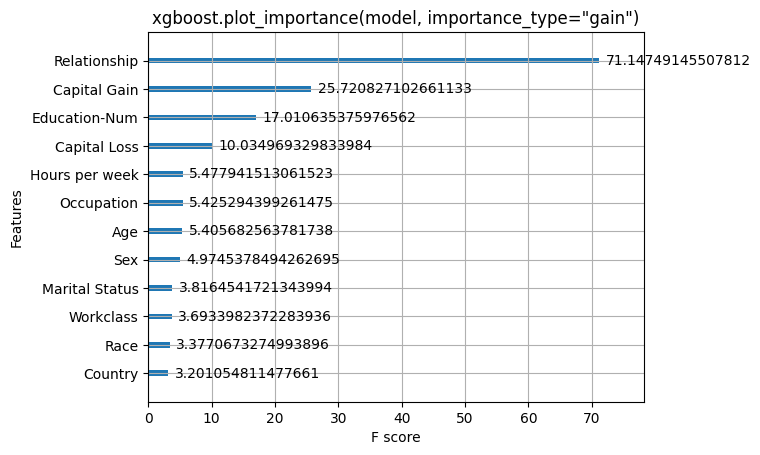
[6]:
xgboost.plot_importance(model, importance_type="gain")
pl.title('xgboost.plot_importance(model, importance_type="gain")')
pl.show()
Explain predictions
Here we use the Tree SHAP implementation integrated into XGBoost to explain the entire dataset (32561 samples).
[7]:
# this takes a minute or two since we are explaining over 30 thousand samples in a model with over a thousand trees
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X)
Visualize a single prediction
Note that we use the “display values” data frame so we get nice strings instead of category codes.
[8]:
shap.force_plot(explainer.expected_value, shap_values[0, :], X_display.iloc[0, :])
[8]:
Have you run `initjs()` in this notebook? If this notebook was from another user you must also trust this notebook (File -> Trust notebook). If you are viewing this notebook on github the Javascript has been stripped for security. If you are using JupyterLab this error is because a JupyterLab extension has not yet been written.
Visualize many predictions
To keep the browser happy we only visualize 1,000 individuals.
[9]:
shap.force_plot(explainer.expected_value, shap_values[:1000, :], X_display.iloc[:1000, :])
[9]:
Have you run `initjs()` in this notebook? If this notebook was from another user you must also trust this notebook (File -> Trust notebook). If you are viewing this notebook on github the Javascript has been stripped for security. If you are using JupyterLab this error is because a JupyterLab extension has not yet been written.
Bar chart of mean importance
This takes the average of the SHAP value magnitudes across the dataset and plots it as a simple bar chart.
[10]:
shap.summary_plot(shap_values, X_display, plot_type="bar")
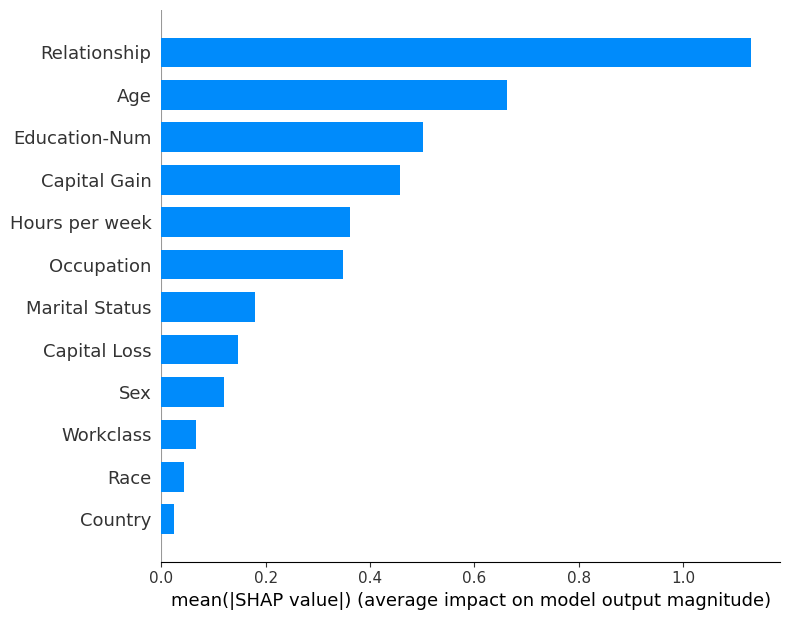
SHAP Summary Plot
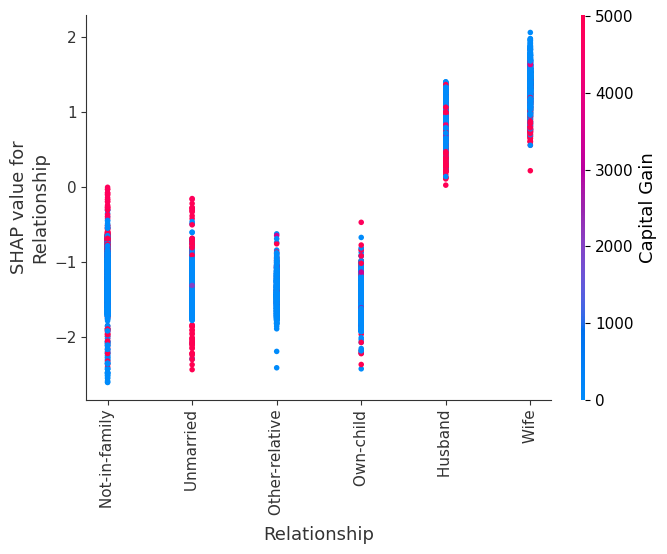
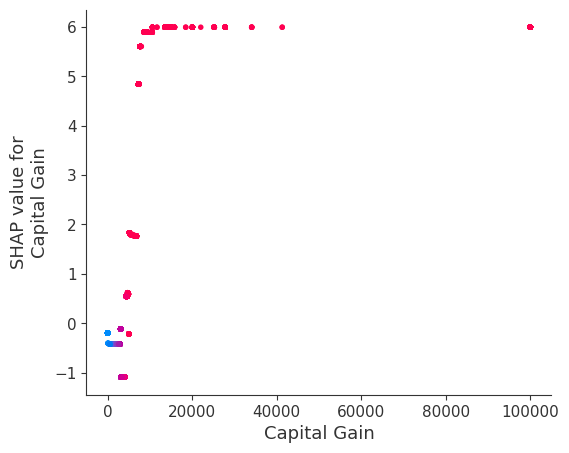
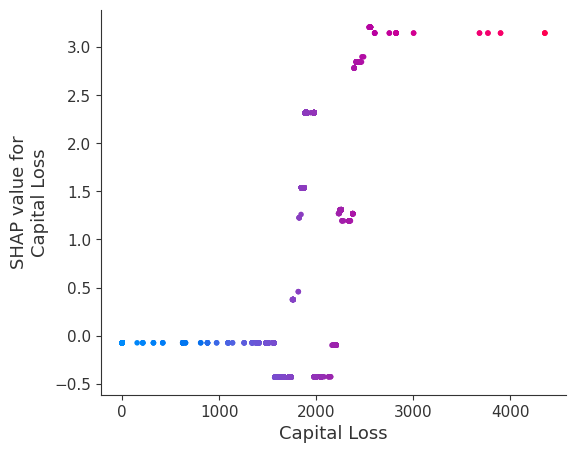
Rather than use a typical feature importance bar chart, we use a density scatter plot of SHAP values for each feature to identify how much impact each feature has on the model output for individuals in the validation dataset. Features are sorted by the sum of the SHAP value magnitudes across all samples. It is interesting to note that the relationship feature has more total model impact than the captial gain feature, but for those samples where capital gain matters it has more impact than age. In other words, capital gain effects a few predictions by a large amount, while age effects all predictions by a smaller amount.
Note that when the scatter points don’t fit on a line they pile up to show density, and the color of each point represents the feature value of that individual.
[11]:
shap.summary_plot(shap_values, X)
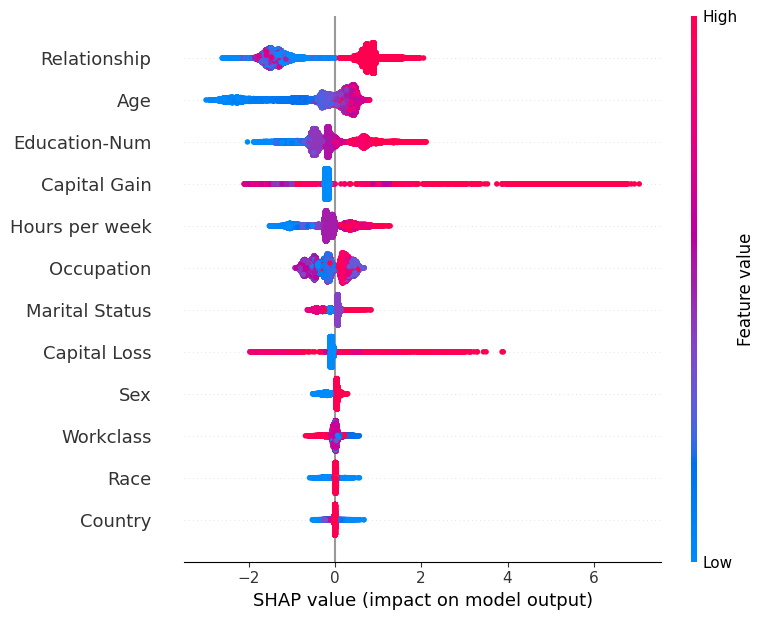
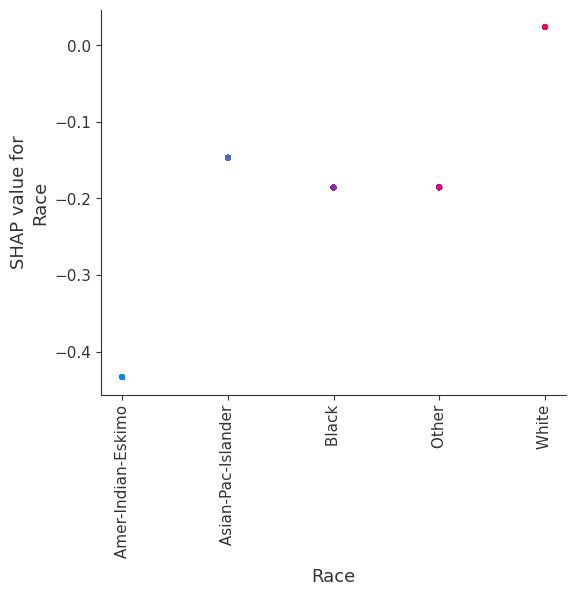
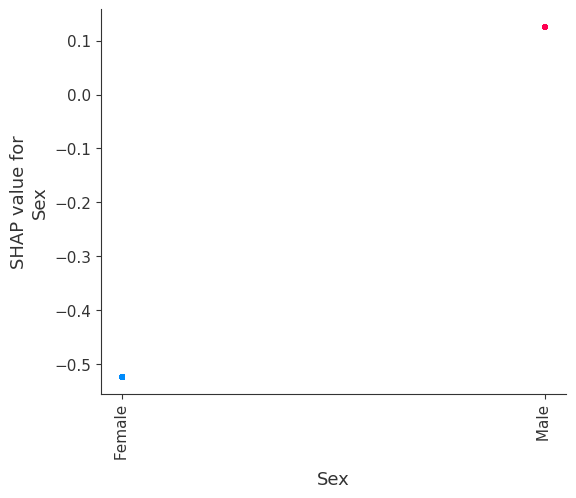
SHAP Dependence Plots
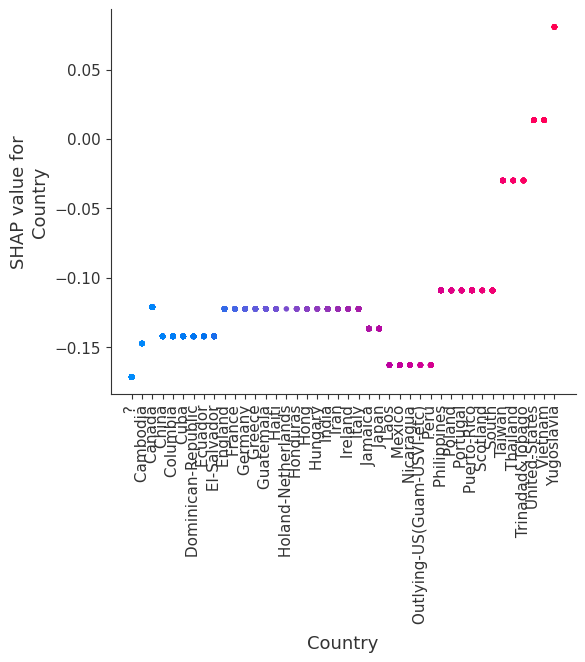
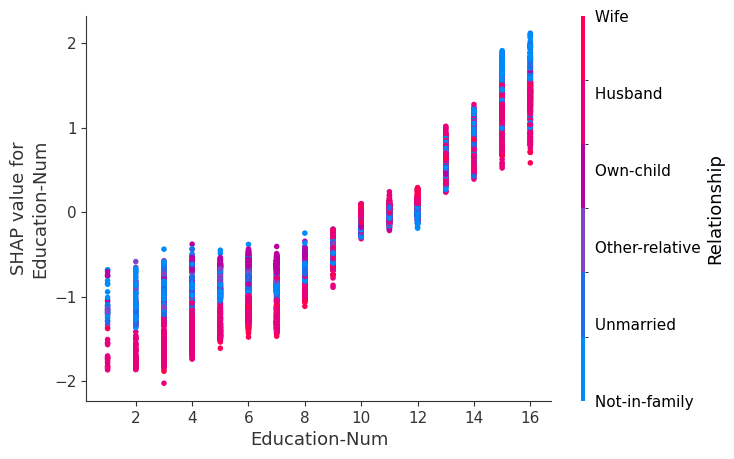
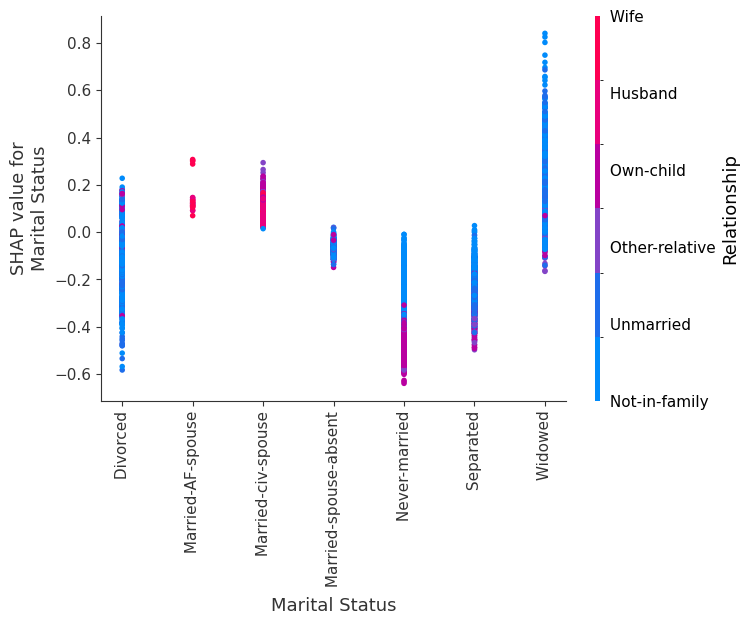
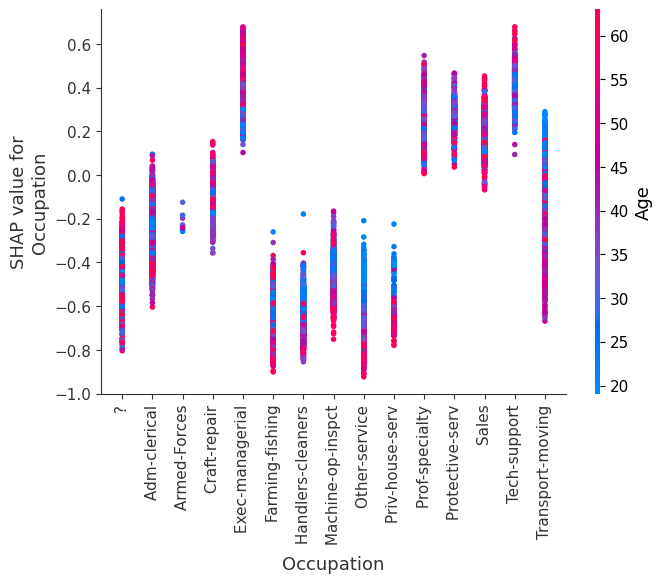
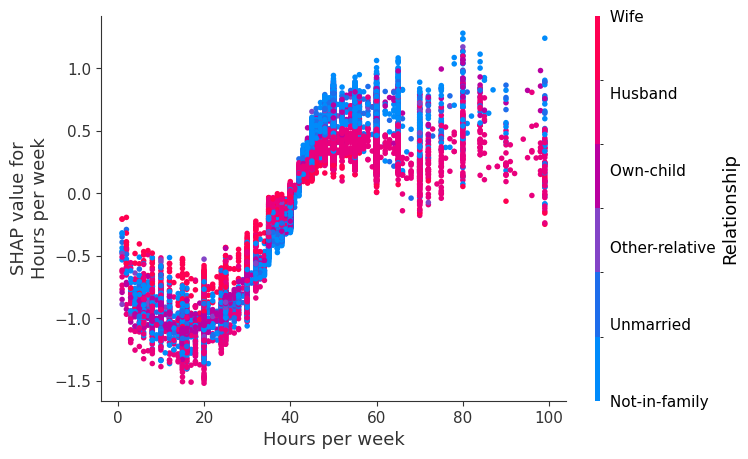
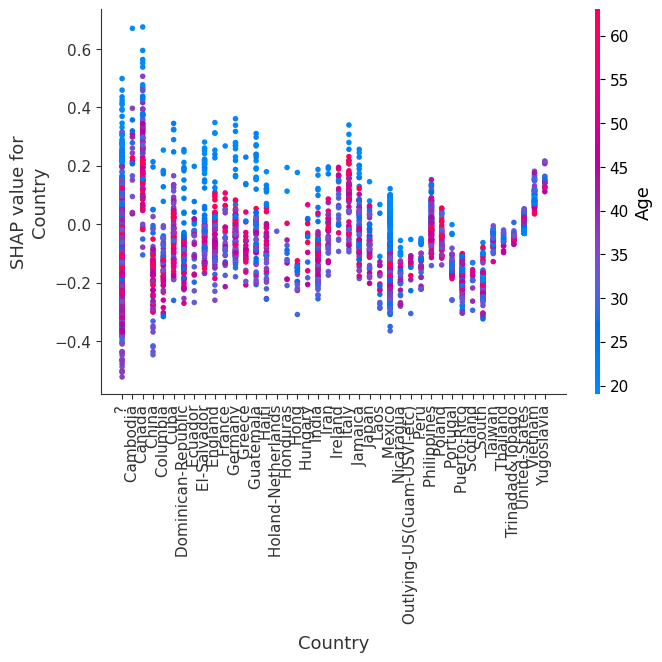
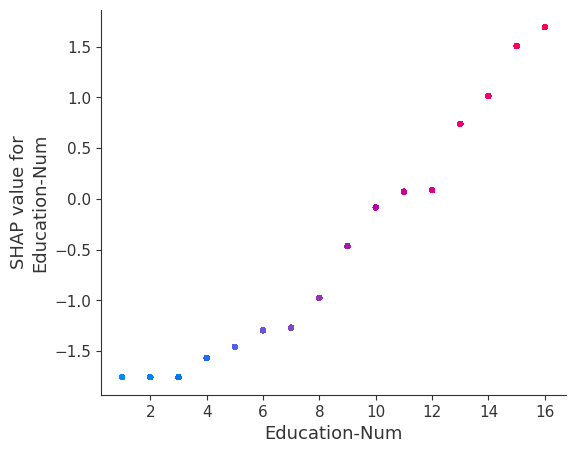
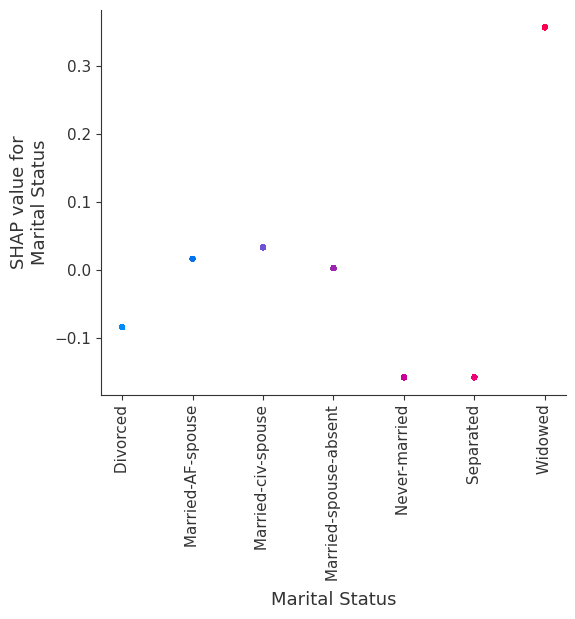
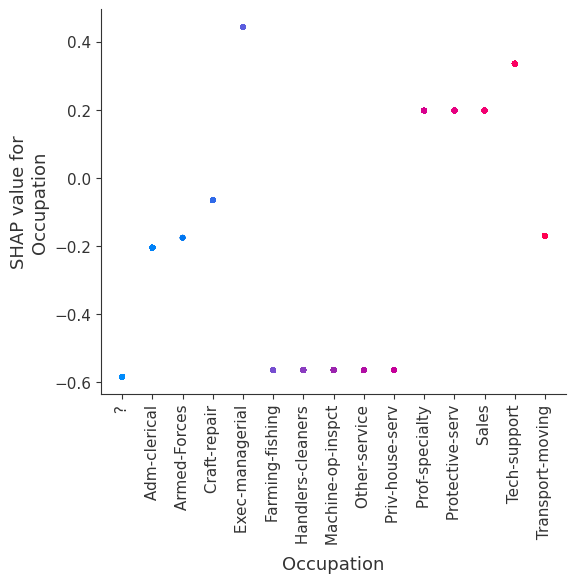
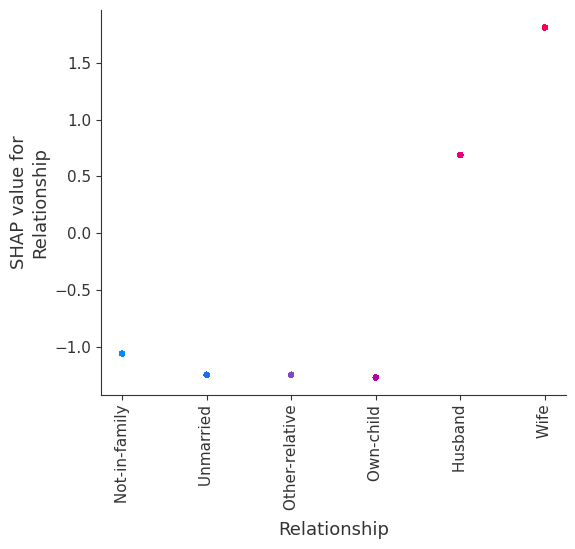
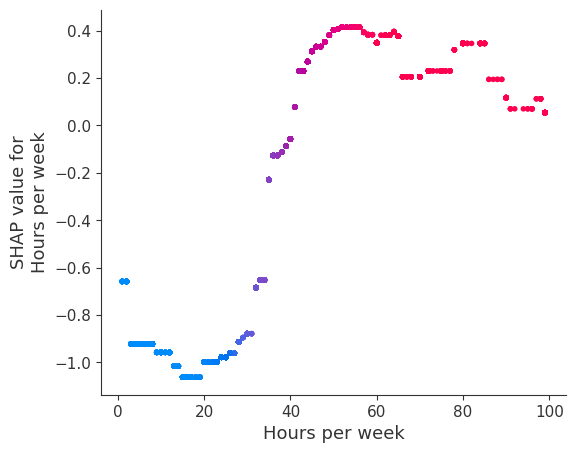
SHAP dependence plots show the effect of a single feature across the whole dataset. They plot a feature’s value vs. the SHAP value of that feature across many samples. SHAP dependence plots are similar to partial dependence plots, but account for the interaction effects present in the features, and are only defined in regions of the input space supported by data. The vertical dispersion of SHAP values at a single feature value is driven by interaction effects, and another feature is chosen for coloring to highlight possible interactions.
[12]:
for name in X_train.columns:
shap.dependence_plot(name, shap_values, X, display_features=X_display)
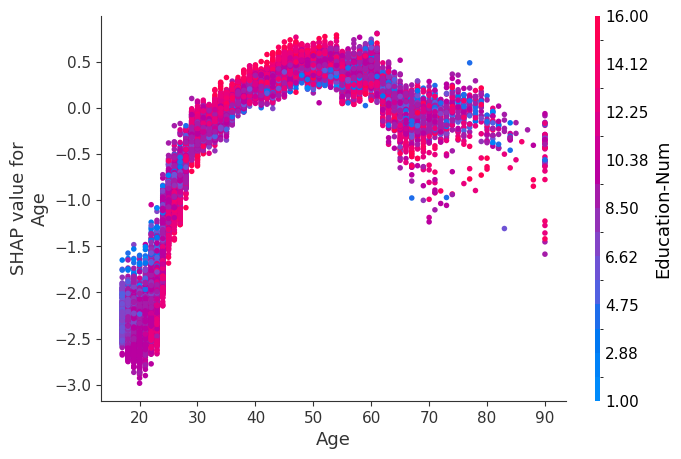
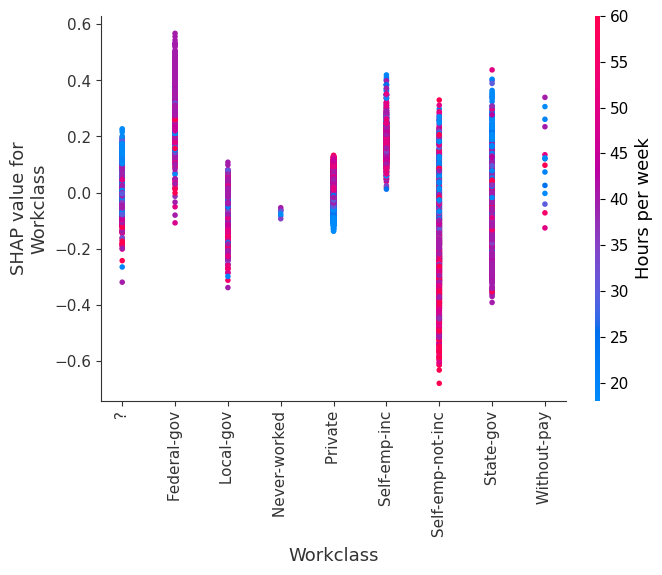
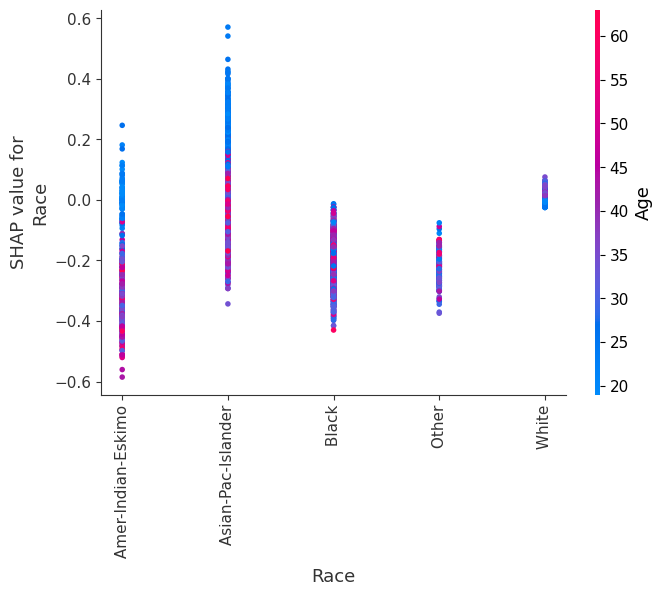
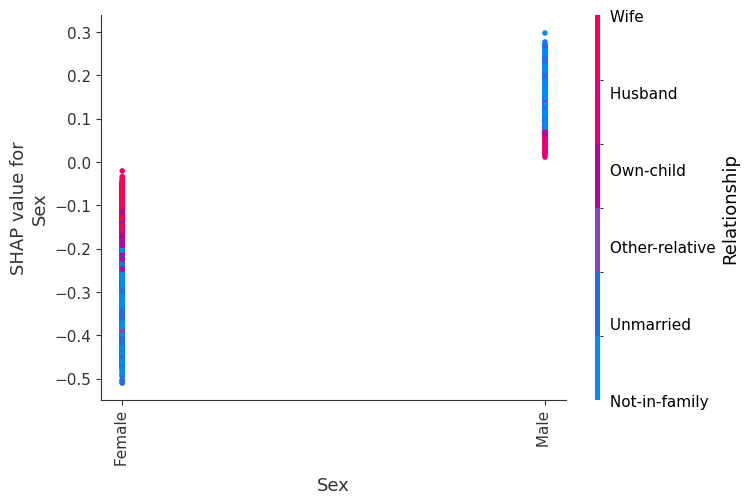
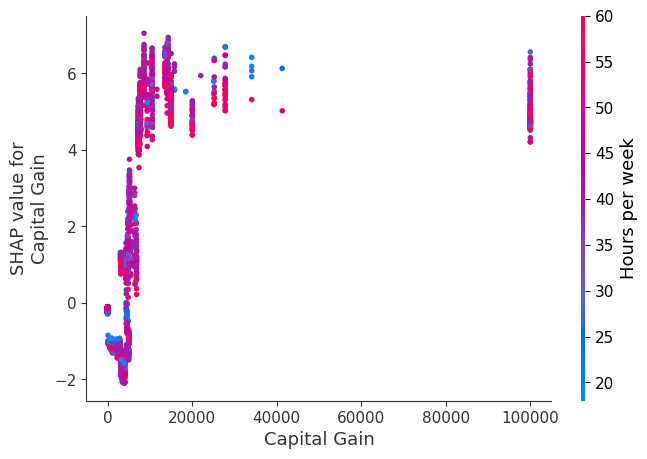
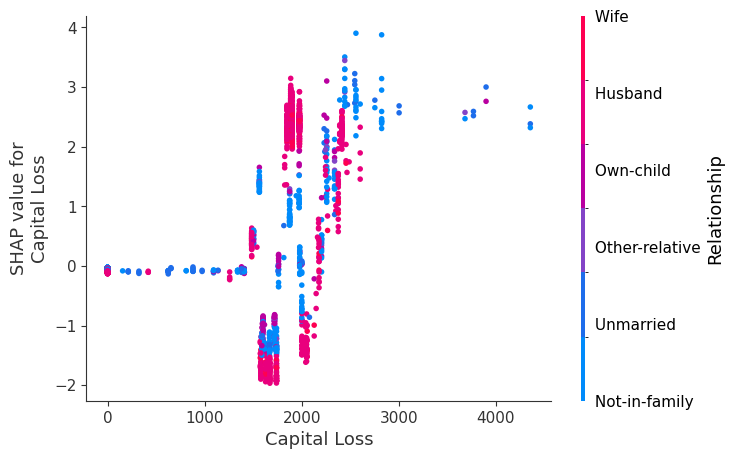
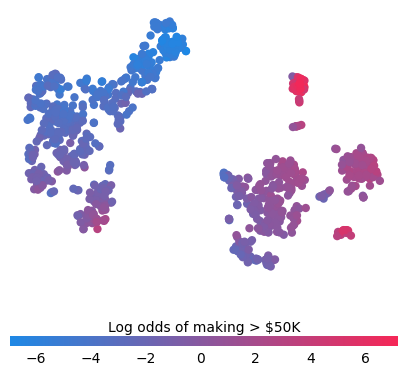
Simple supervised clustering
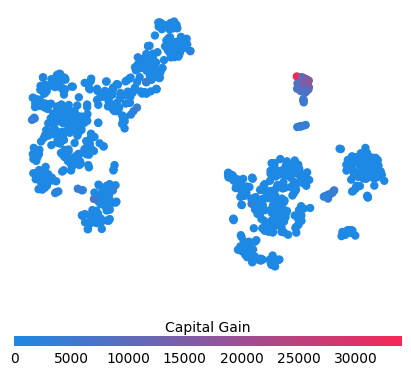
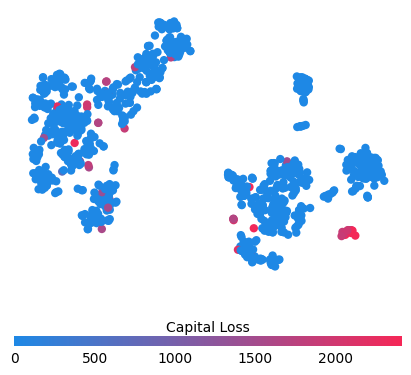
Clustering people by their shap_values leads to groups relevent to the prediction task at hand (their earning potential in this case).
[13]:
from sklearn.decomposition import PCA
from sklearn.manifold import TSNE
shap_pca50 = PCA(n_components=12).fit_transform(shap_values[:1000, :])
shap_embedded = TSNE(n_components=2, perplexity=50).fit_transform(shap_values[:1000, :])
[14]:
from matplotlib.colors import LinearSegmentedColormap
cdict1 = {
"red": (
(0.0, 0.11764705882352941, 0.11764705882352941),
(1.0, 0.9607843137254902, 0.9607843137254902),
),
"green": (
(0.0, 0.5333333333333333, 0.5333333333333333),
(1.0, 0.15294117647058825, 0.15294117647058825),
),
"blue": (
(0.0, 0.8980392156862745, 0.8980392156862745),
(1.0, 0.3411764705882353, 0.3411764705882353),
),
"alpha": ((0.0, 1, 1), (0.5, 1, 1), (1.0, 1, 1)),
} # #1E88E5 -> #ff0052
red_blue_solid = LinearSegmentedColormap("RedBlue", cdict1)
[15]:
f = pl.figure(figsize=(5, 5))
pl.scatter(
shap_embedded[:, 0],
shap_embedded[:, 1],
c=shap_values[:1000, :].sum(1).astype(np.float64),
linewidth=0,
alpha=1.0,
cmap=red_blue_solid,
)
cb = pl.colorbar(label="Log odds of making > $50K", aspect=40, orientation="horizontal")
cb.set_alpha(1)
cb.outline.set_linewidth(0)
cb.ax.tick_params("x", length=0)
cb.ax.xaxis.set_label_position("top")
pl.gca().axis("off")
pl.show()
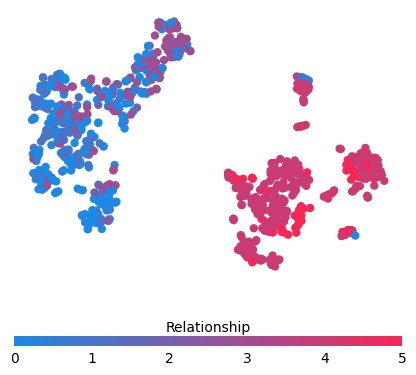
[16]:
for feature in ["Relationship", "Capital Gain", "Capital Loss"]:
f = pl.figure(figsize=(5, 5))
pl.scatter(
shap_embedded[:, 0],
shap_embedded[:, 1],
c=X[feature].values[:1000].astype(np.float64),
linewidth=0,
alpha=1.0,
cmap=red_blue_solid,
)
cb = pl.colorbar(label=feature, aspect=40, orientation="horizontal")
cb.set_alpha(1)
cb.outline.set_linewidth(0)
cb.ax.tick_params("x", length=0)
cb.ax.xaxis.set_label_position("top")
pl.gca().axis("off")
pl.show()
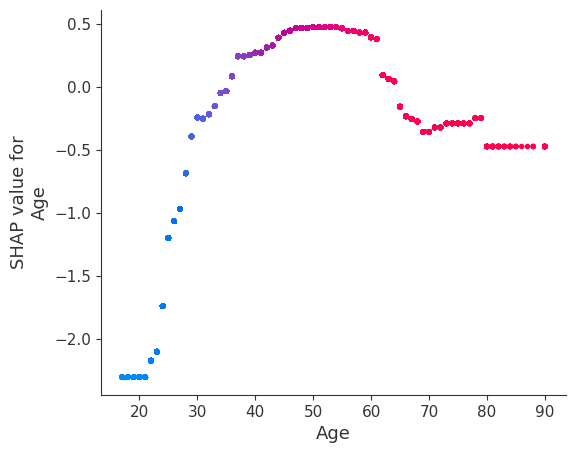
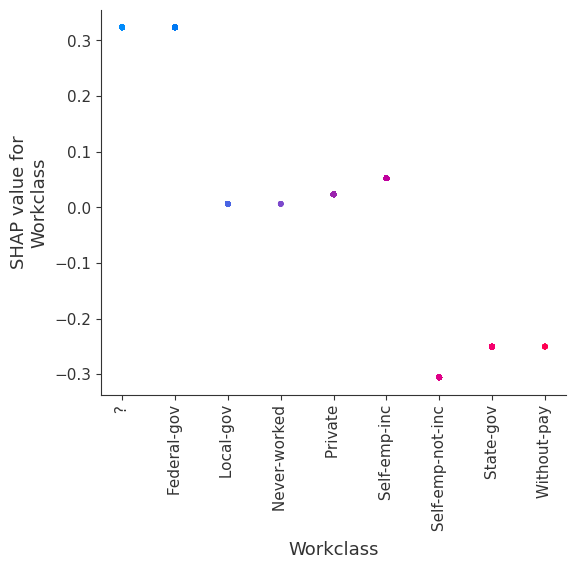
Train a model with only two leaves per tree and hence no interaction terms between features
Forcing the model to have no interaction terms means the effect of a feature on the outcome does not depend on the value of any other feature. This is reflected in the SHAP dependence plots below as no vertical spread. A vertical spread reflects that a single value of a feature can have different effects on the model output depending on the context of the other features present for an individual. However, for models without interaction terms, a feature always has the same impact regardless of what other attributes an individual may have.
One the benefits of SHAP dependence plots over traditional partial dependence plots is this ability to distigush between models with and without interaction terms. In other words, SHAP dependence plots give an idea of the magnitude of the interaction terms through the vertical variance of the scatter plot at a given feature value.
[17]:
# train final model on the full data set
params = {
"eta": 0.05,
"max_depth": 1,
"objective": "binary:logistic",
"subsample": 0.5,
"base_score": np.mean(y_train),
"eval_metric": "logloss",
}
model_ind = xgboost.train(
params,
d_train,
5000,
evals=[(d_test, "test")],
verbose_eval=100,
early_stopping_rounds=20,
)
[0] test-logloss:0.54113
[100] test-logloss:0.35499
[200] test-logloss:0.32848
[300] test-logloss:0.31901
[400] test-logloss:0.31331
[500] test-logloss:0.30930
[600] test-logloss:0.30619
[700] test-logloss:0.30371
[800] test-logloss:0.30184
[900] test-logloss:0.30035
[1000] test-logloss:0.29913
[1100] test-logloss:0.29796
[1200] test-logloss:0.29695
[1300] test-logloss:0.29606
[1400] test-logloss:0.29525
[1500] test-logloss:0.29471
[1565] test-logloss:0.29439
[18]:
shap_values_ind = shap.TreeExplainer(model_ind).shap_values(X)
Note that the interaction color bars below are meaningless for this model because it has no interactions.
[19]:
for name in X_train.columns:
shap.dependence_plot(name, shap_values_ind, X, display_features=X_display)
invalid value encountered in divide
invalid value encountered in divide
invalid value encountered in divide
invalid value encountered in divide
invalid value encountered in divide
invalid value encountered in divide
invalid value encountered in divide
invalid value encountered in divide
invalid value encountered in divide
invalid value encountered in divide
invalid value encountered in divide
invalid value encountered in divide
invalid value encountered in divide
invalid value encountered in divide
invalid value encountered in divide
invalid value encountered in divide
invalid value encountered in divide
invalid value encountered in divide
invalid value encountered in divide
invalid value encountered in divide
invalid value encountered in divide
invalid value encountered in divide
invalid value encountered in divide
invalid value encountered in divide