An introduction to explainable AI with Shapley values
This is an introduction to explaining machine learning models with Shapley values. Shapley values are a widely used approach from cooperative game theory that come with desirable properties. This tutorial is designed to help build a solid understanding of how to compute and interpet Shapley-based explanations of machine learning models. We will take a practical hands-on approach, using the shap Python package to explain progressively more complex models. This is a living document, and serves
as an introduction to the shap Python package. So if you have feedback or contributions please open an issue or pull request to make this tutorial better!
Outline
Explaining a linear regression model
Explaining a generalized additive regression model
Explaining a non-additive boosted tree model
Explaining a linear logistic regression model
Explaining a non-additive boosted tree logistic regression model
Dealing with correlated input features
Explaining a transformers NLP model
Explaining a linear regression model
Before using Shapley values to explain complicated models, it is helpful to understand how they work for simple models. One of the simplest model types is standard linear regression, and so below we train a linear regression model on the California housing dataset. This dataset consists of 20,640 blocks of houses across California in 1990, where our goal is to predict the natural log of the median home price from 8 different features:
MedInc - median income in block group
HouseAge - median house age in block group
AveRooms - average number of rooms per household
AveBedrms - average number of bedrooms per household
Population - block group population
AveOccup - average number of household members
Latitude - block group latitude
Longitude - block group longitude
[1]:
import sklearn
import shap
# a classic housing price dataset
X, y = shap.datasets.california(n_points=1000)
X100 = shap.utils.sample(X, 100) # 100 instances for use as the background distribution
# a simple linear model
model = sklearn.linear_model.LinearRegression()
model.fit(X, y)
[1]:
LinearRegression()
Examining the model coefficients
The most common way of understanding a linear model is to examine the coefficients learned for each feature. These coefficients tell us how much the model output changes when we change each of the input features:
[2]:
print("Model coefficients:\n")
for i in range(X.shape[1]):
print(X.columns[i], "=", model.coef_[i].round(5))
Model coefficients:
MedInc = 0.45769
HouseAge = 0.01153
AveRooms = -0.12529
AveBedrms = 1.04053
Population = 5e-05
AveOccup = -0.29795
Latitude = -0.41204
Longitude = -0.40125
While coefficients are great for telling us what will happen when we change the value of an input feature, by themselves they are not a great way to measure the overall importance of a feature. This is because the value of each coefficient depends on the scale of the input features. If for example we were to measure the age of a home in minutes instead of years, then the coefficients for the HouseAge feature would become 0.0115 / (365∗24∗60) = 2.18e-8. Clearly the number of years since a house was built is not more important than the number of minutes, yet its coefficient value is much larger. This means that the magnitude of a coefficient is not necessarily a good measure of a feature’s importance in a linear model.
A more complete picture using partial dependence plots
To understand a feature’s importance in a model, it is necessary to understand both how changing that feature impacts the model’s output, and also the distribution of that feature’s values. To visualize this for a linear model we can build a classical partial dependence plot and show the distribution of feature values as a histogram on the x-axis:
[3]:
shap.partial_dependence_plot(
"MedInc",
model.predict,
X100,
ice=False,
model_expected_value=True,
feature_expected_value=True,
)
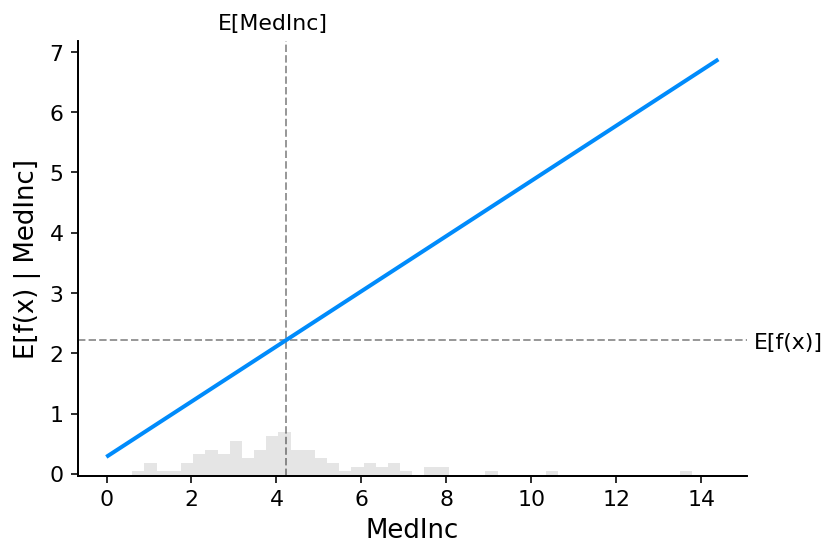
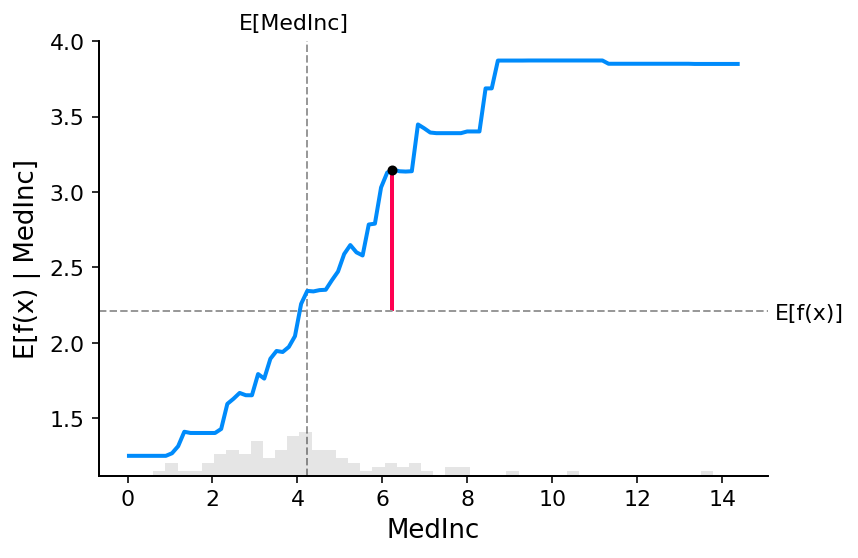
The gray horizontal line in the plot above represents the expected value of the model when applied to the California housing dataset. The vertical gray line represents the average value of the median income feature. Note that the blue partial dependence plot line (which is the average value of the model output when we fix the median income feature to a given value) always passes through the intersection of the two gray expected value lines. We can consider this intersection point as the “center” of the partial dependence plot with respect to the data distribution. The impact of this centering will become clear when we turn to Shapley values next.
Reading SHAP values from partial dependence plots
The core idea behind Shapley value based explanations of machine learning models is to use fair allocation results from cooperative game theory to allocate credit for a model’s output \(f(x)\) among its input features. In order to connect game theory with machine learning models, it is necessary to both match a model’s input features with players in a game, and also match the model function with the rules of the game. Since in game theory a player can join or not join a game, we need a way for a feature to “join” or “not join” a model. The most common way to define what it means for a feature to “join” a model is to say that feature has “joined a model” when we know the value of that feature, and it has not joined a model when we don’t know the value of that feature. To evaluate an existing model \(f\) when only a subset \(S\) of features are part of the model we integrate out the other features using a conditional expected value formulation. This formulation can take two forms:
or
In the first form we know the values of the features in S because we observe them. In the second form we know the values of the features in S because we set them. In general, the second form is usually preferable, both because it tells us how the model would behave if we were to intervene and change its inputs, and also because it is much easier to compute. In this tutorial we will focus entirely on the second formulation. We will also use the more specific term “SHAP values” to refer to Shapley values applied to a conditional expectation function of a machine learning model.
SHAP values can be very complicated to compute (they are NP-hard in general), but linear models are so simple that we can read the SHAP values right off a partial dependence plot. When we are explaining a prediction \(f(x)\), the SHAP value for a specific feature \(i\) is just the difference between the expected model output and the partial dependence plot at the feature’s value \(x_i\):
[4]:
# compute the SHAP values for the linear model
explainer = shap.Explainer(model.predict, X100)
shap_values = explainer(X)
# make a standard partial dependence plot
sample_ind = 20
shap.partial_dependence_plot(
"MedInc",
model.predict,
X100,
model_expected_value=True,
feature_expected_value=True,
ice=False,
shap_values=shap_values[sample_ind : sample_ind + 1, :],
)
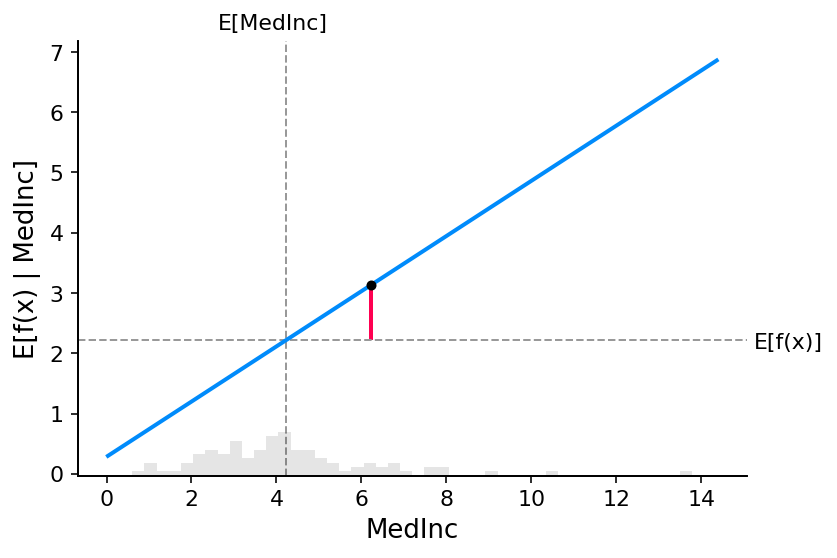
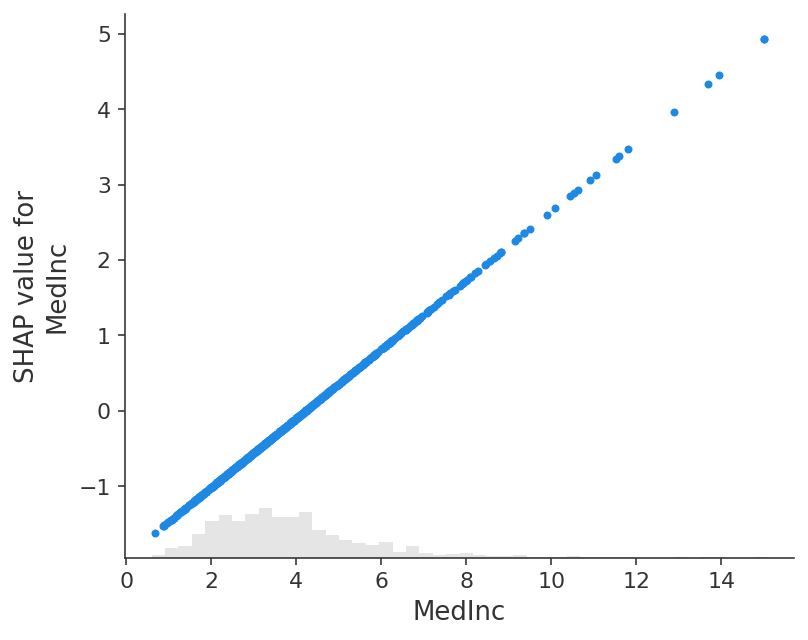
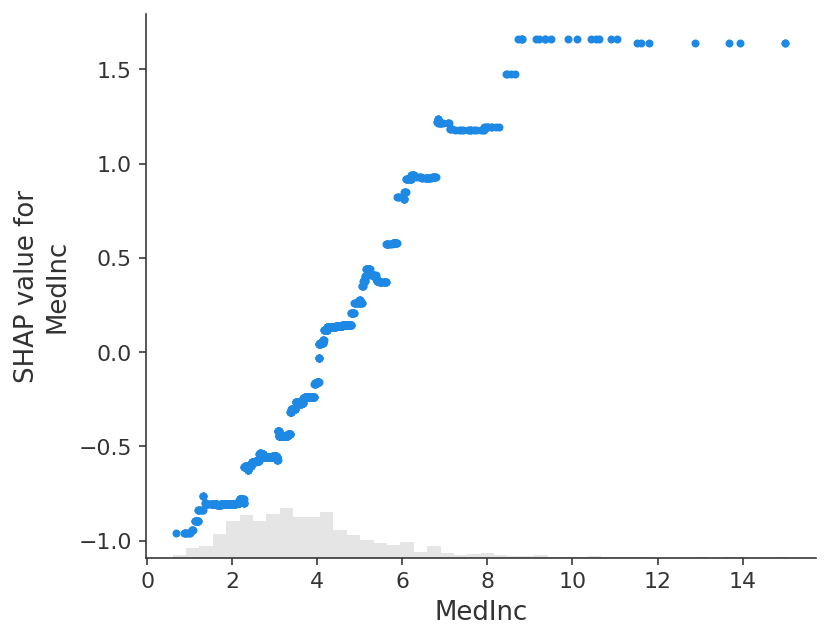
The close correspondence between the classic partial dependence plot and SHAP values means that if we plot the SHAP value for a specific feature across a whole dataset we will exactly trace out a mean centered version of the partial dependence plot for that feature:
[5]:
shap.plots.scatter(shap_values[:, "MedInc"])
The additive nature of Shapley values
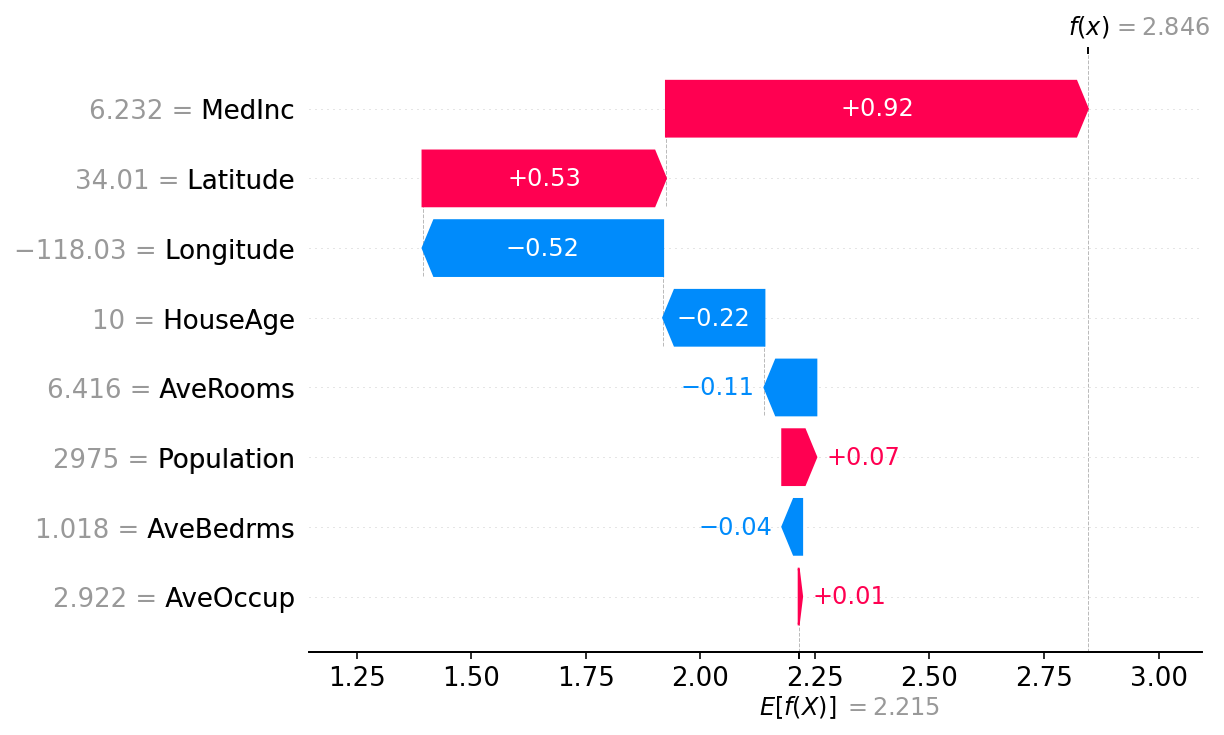
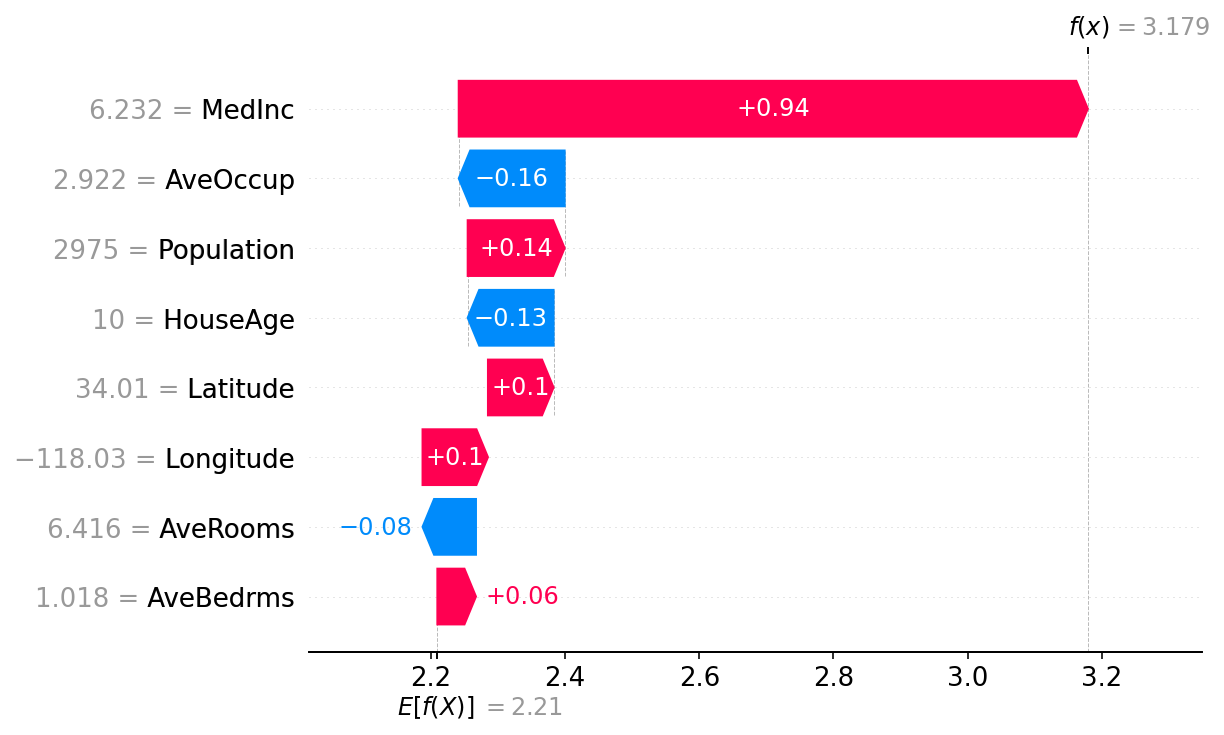
One of the fundamental properties of Shapley values is that they always sum up to the difference between the game outcome when all players are present and the game outcome when no players are present. For machine learning models this means that SHAP values of all the input features will always sum up to the difference between baseline (expected) model output and the current model output for the prediction being explained. The easiest way to see this is through a waterfall plot that starts at our background prior expectation for a home price \(E[f(X)]\), and then adds features one at a time until we reach the current model output \(f(x)\):
[6]:
# the waterfall_plot shows how we get from shap_values.base_values to model.predict(X)[sample_ind]
shap.plots.waterfall(shap_values[sample_ind], max_display=14)
Explaining an additive regression model
The reason the partial dependence plots of linear models have such a close connection to SHAP values is because each feature in the model is handled independently of every other feature (the effects are just added together). We can keep this additive nature while relaxing the linear requirement of straight lines. This results in the well-known class of generalized additive models (GAMs). While there are many ways to train these types of models (like setting an XGBoost model to depth-1), we will use InterpretMLs explainable boosting machines that are specifically designed for this.
[7]:
# fit a GAM model to the data
import interpret.glassbox
model_ebm = interpret.glassbox.ExplainableBoostingRegressor(interactions=0)
model_ebm.fit(X, y)
# explain the GAM model with SHAP
explainer_ebm = shap.Explainer(model_ebm.predict, X100)
shap_values_ebm = explainer_ebm(X)
# make a standard partial dependence plot with a single SHAP value overlaid
fig, ax = shap.partial_dependence_plot(
"MedInc",
model_ebm.predict,
X100,
model_expected_value=True,
feature_expected_value=True,
show=False,
ice=False,
shap_values=shap_values_ebm[sample_ind : sample_ind + 1, :],
)
[8]:
shap.plots.scatter(shap_values_ebm[:, "MedInc"])
[9]:
# the waterfall_plot shows how we get from explainer.expected_value to model.predict(X)[sample_ind]
shap.plots.waterfall(shap_values_ebm[sample_ind])
[10]:
# the beeswarm plot displays SHAP values for each feature across all examples,
# with colors indicating how the SHAP values correlate with feature values
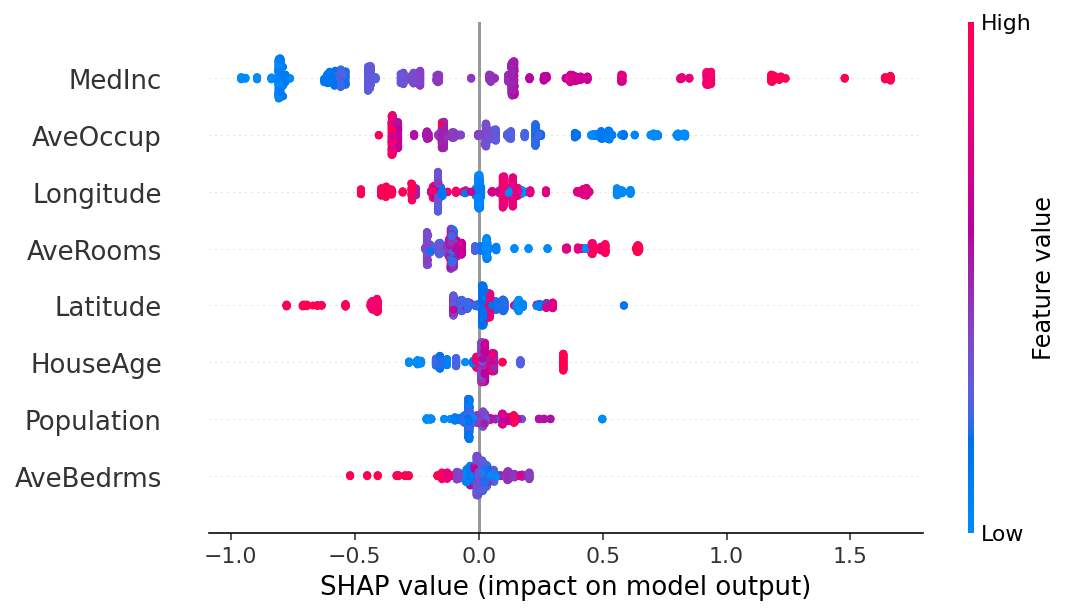
shap.plots.beeswarm(shap_values_ebm)
Explaining a non-additive boosted tree model
[11]:
# train XGBoost model
import xgboost
model_xgb = xgboost.XGBRegressor(n_estimators=100, max_depth=2).fit(X, y)
# explain the GAM model with SHAP
explainer_xgb = shap.Explainer(model_xgb, X100)
shap_values_xgb = explainer_xgb(X)
# make a standard partial dependence plot with a single SHAP value overlaid
fig, ax = shap.partial_dependence_plot(
"MedInc",
model_xgb.predict,
X100,
model_expected_value=True,
feature_expected_value=True,
show=False,
ice=False,
shap_values=shap_values_xgb[sample_ind : sample_ind + 1, :],
)
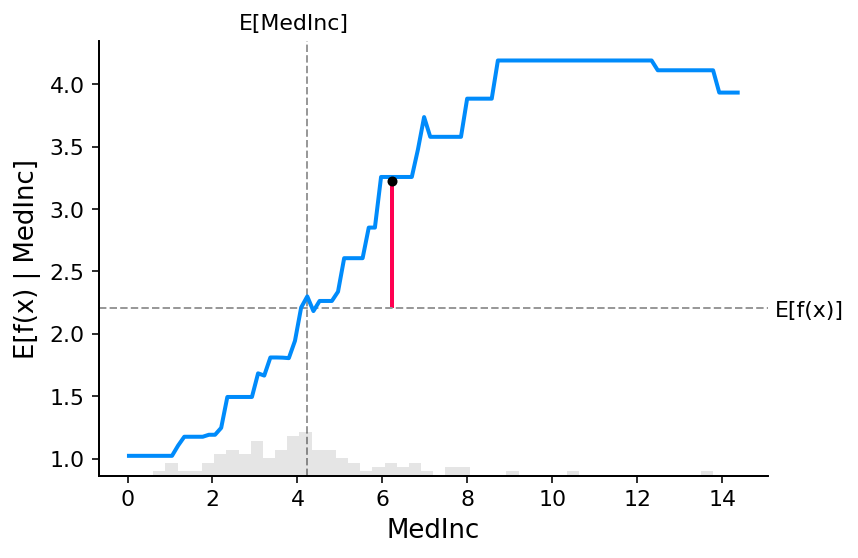
[12]:
shap.plots.scatter(shap_values_xgb[:, "MedInc"])
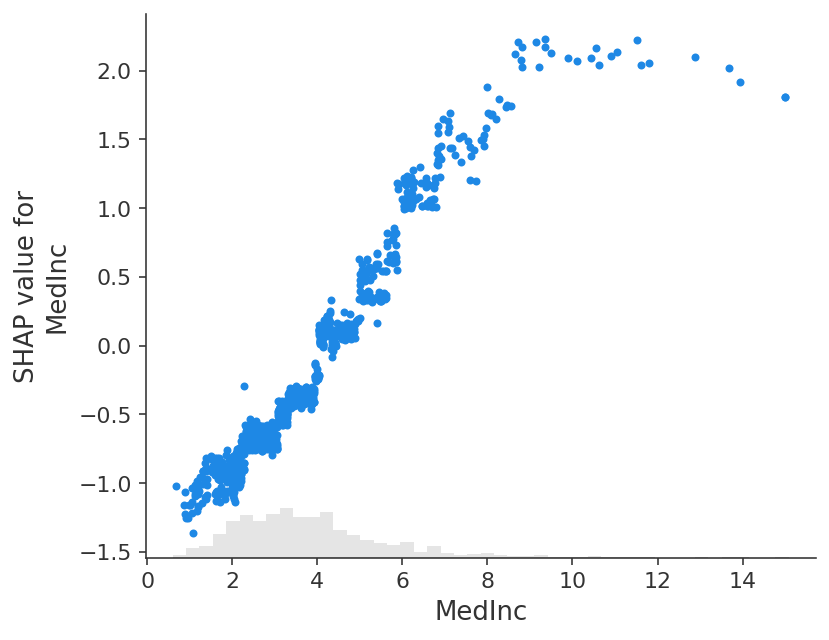
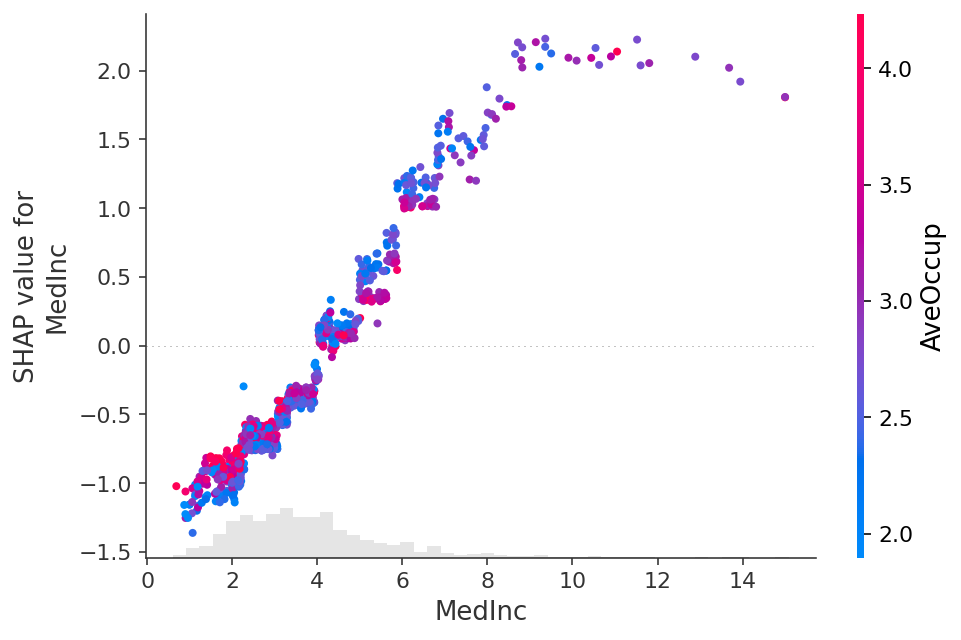
[13]:
shap.plots.scatter(shap_values_xgb[:, "MedInc"], color=shap_values)
Explaining a linear logistic regression model
[14]:
# a classic adult census dataset price dataset
X_adult, y_adult = shap.datasets.adult()
# a simple linear logistic model
model_adult = sklearn.linear_model.LogisticRegression(max_iter=10000)
model_adult.fit(X_adult, y_adult)
def model_adult_proba(x):
return model_adult.predict_proba(x)[:, 1]
def model_adult_log_odds(x):
p = model_adult.predict_log_proba(x)
return p[:, 1] - p[:, 0]
Note that explaining the probability of a linear logistic regression model is not linear in the inputs.
[15]:
# make a standard partial dependence plot
sample_ind = 18
fig, ax = shap.partial_dependence_plot(
"Capital Gain",
model_adult_proba,
X_adult,
model_expected_value=True,
feature_expected_value=True,
show=False,
ice=False,
)
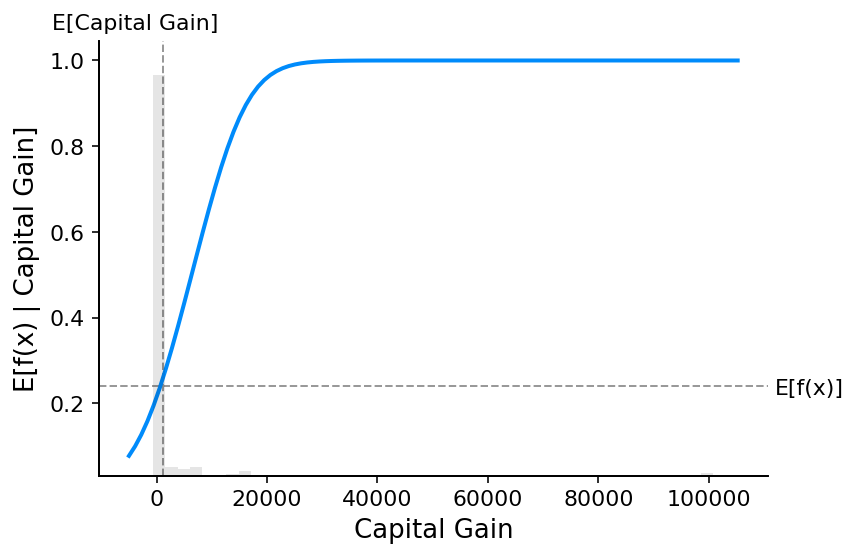
If we use SHAP to explain the probability of a linear logistic regression model we see strong interaction effects. This is because a linear logistic regression model is NOT additive in the probability space.
[16]:
# compute the SHAP values for the linear model
background_adult = shap.maskers.Independent(X_adult, max_samples=100)
explainer = shap.Explainer(model_adult_proba, background_adult)
shap_values_adult = explainer(X_adult[:1000])
Permutation explainer: 1001it [00:58, 14.39it/s]
[17]:
shap.plots.scatter(shap_values_adult[:, "Age"])
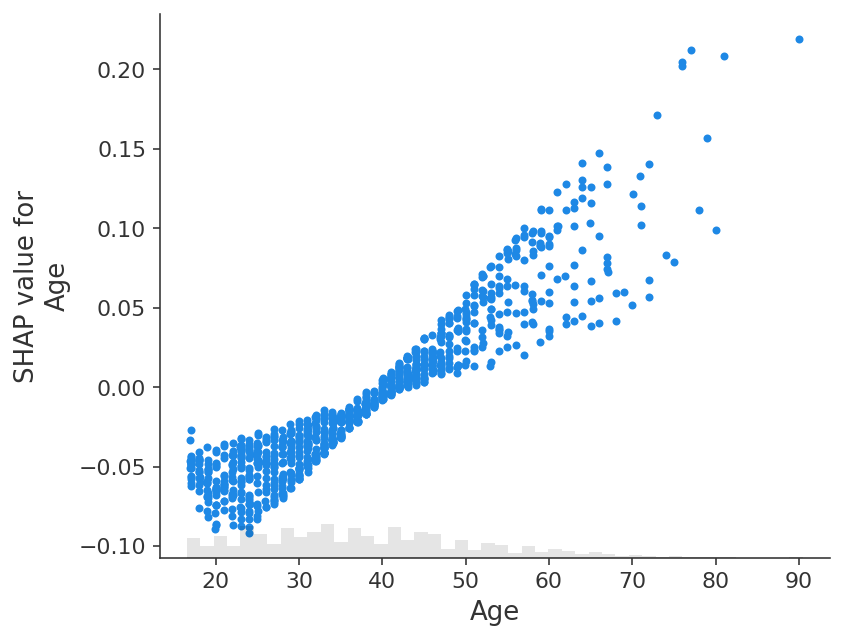
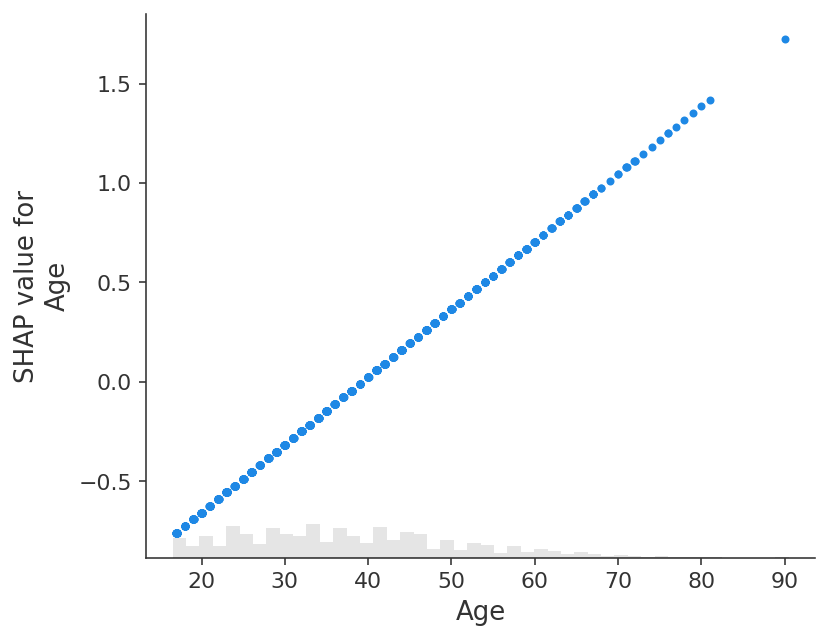
If we instead explain the log-odds output of the model we see a perfect linear relationship between the models inputs and the model’s outputs. It is important to remember what the units are of the model you are explaining, and that explaining different model outputs can lead to very different views of the model’s behavior.
[18]:
# compute the SHAP values for the linear model
explainer_log_odds = shap.Explainer(model_adult_log_odds, background_adult)
shap_values_adult_log_odds = explainer_log_odds(X_adult[:1000])
Permutation explainer: 1001it [01:01, 13.61it/s]
[19]:
shap.plots.scatter(shap_values_adult_log_odds[:, "Age"])
[20]:
# make a standard partial dependence plot
sample_ind = 18
fig, ax = shap.partial_dependence_plot(
"Age",
model_adult_log_odds,
X_adult,
model_expected_value=True,
feature_expected_value=True,
show=False,
ice=False,
)
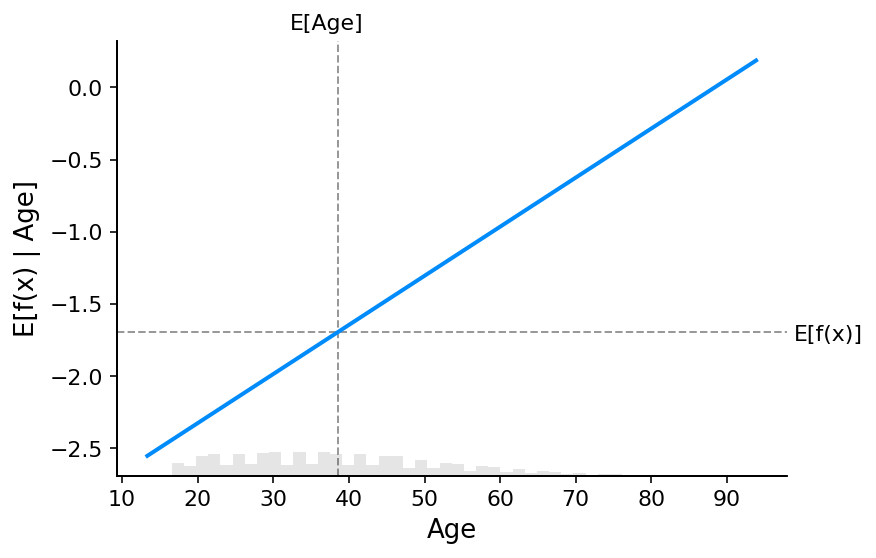
Explaining a non-additive boosted tree logistic regression model
[21]:
# train XGBoost model
model = xgboost.XGBClassifier(n_estimators=100, max_depth=2).fit(X_adult, y_adult * 1, eval_metric="logloss")
# compute SHAP values
explainer = shap.Explainer(model, background_adult)
shap_values = explainer(X_adult)
# set a display version of the data to use for plotting (has string values)
shap_values.display_data = shap.datasets.adult(display=True)[0].values
The use of label encoder in XGBClassifier is deprecated and will be removed in a future release. To remove this warning, do the following: 1) Pass option use_label_encoder=False when constructing XGBClassifier object; and 2) Encode your labels (y) as integers starting with 0, i.e. 0, 1, 2, ..., [num_class - 1].
98%|===================| 31839/32561 [00:12<00:00]
By default a SHAP bar plot will take the mean absolute value of each feature over all the instances (rows) of the dataset.
[22]:
shap.plots.bar(shap_values)
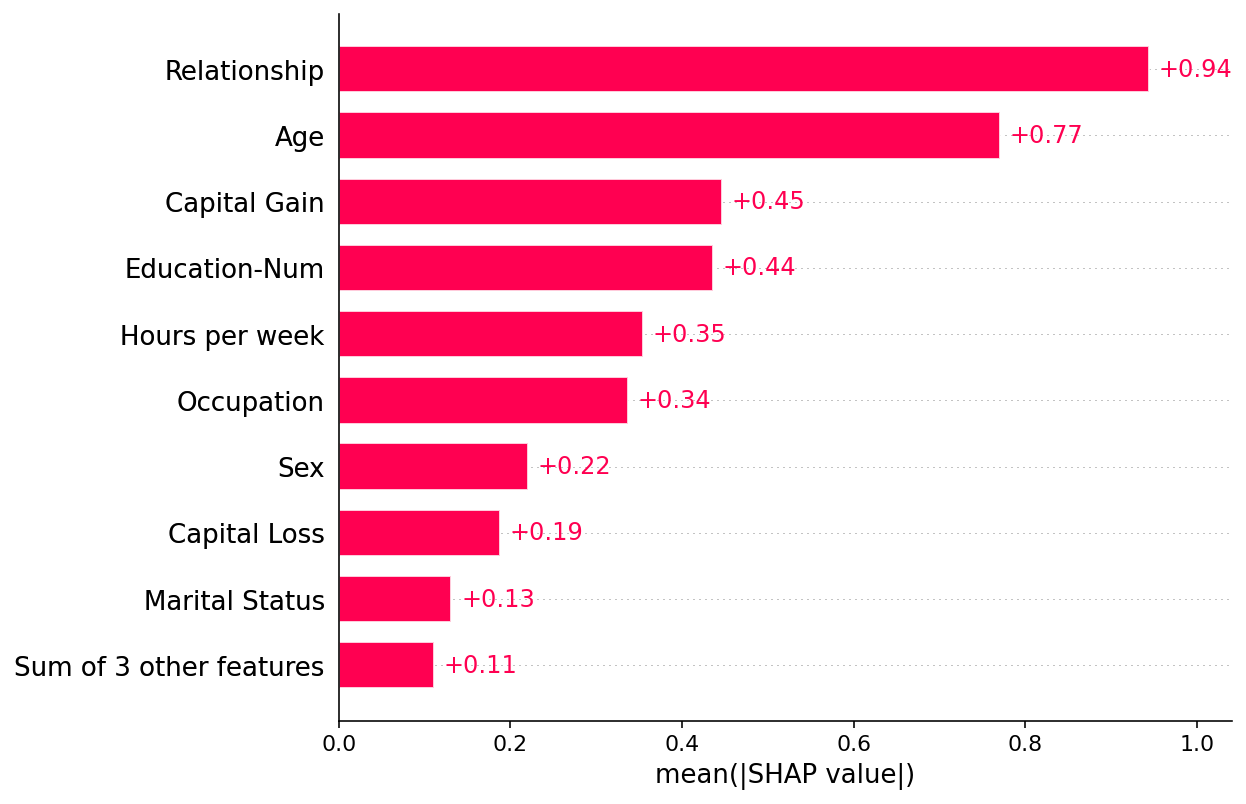
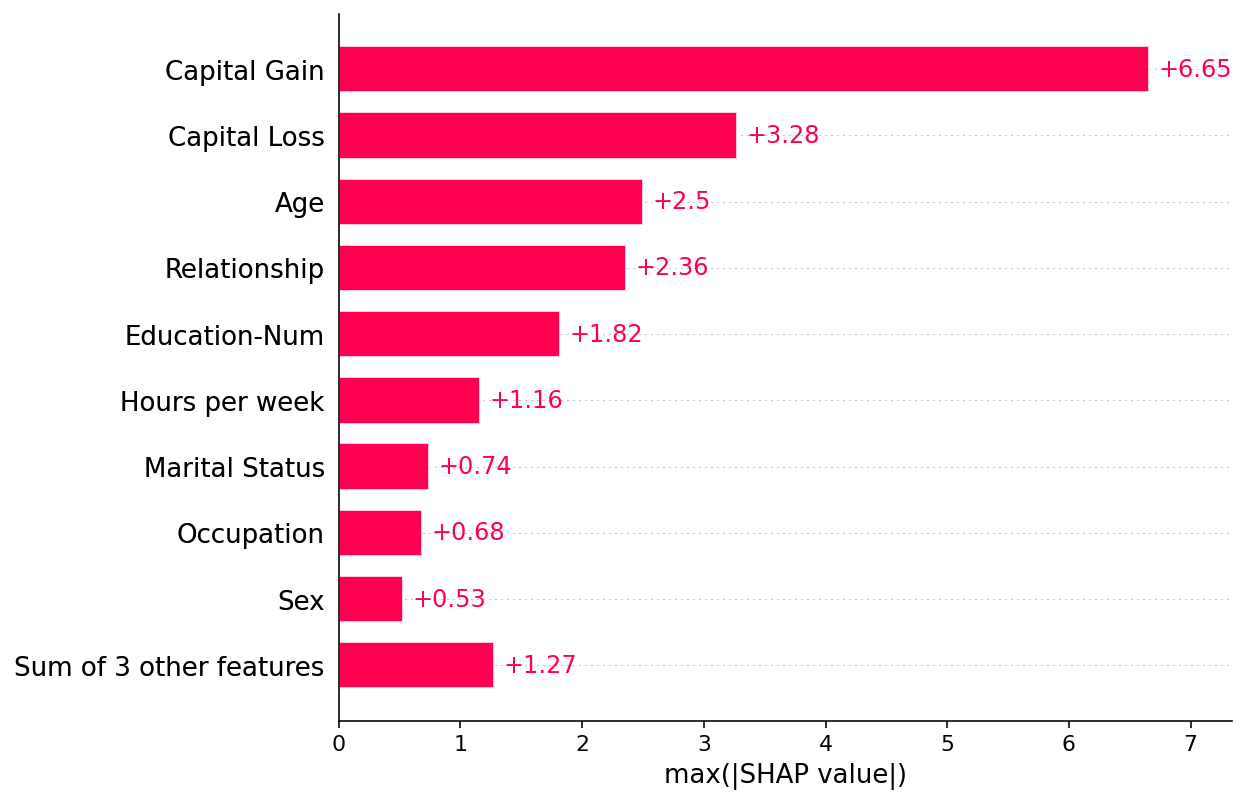
But the mean absolute value is not the only way to create a global measure of feature importance, we can use any number of transforms. Here we show how using the max absolute value highights the Capital Gain and Capital Loss features, since they have infrequent but high magnitude effects.
[23]:
shap.plots.bar(shap_values.abs.max(0))
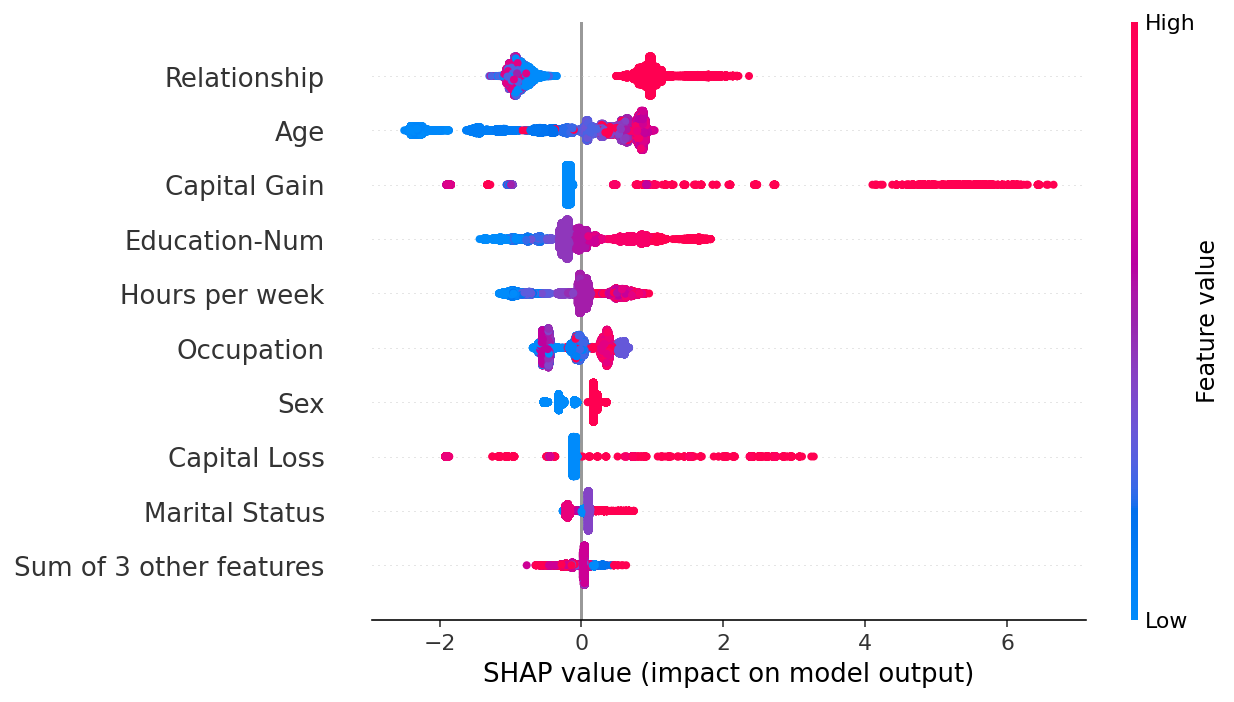
If we are willing to deal with a bit more complexity, we can use a beeswarm plot to summarize the entire distribution of SHAP values for each feature.
[24]:
shap.plots.beeswarm(shap_values)
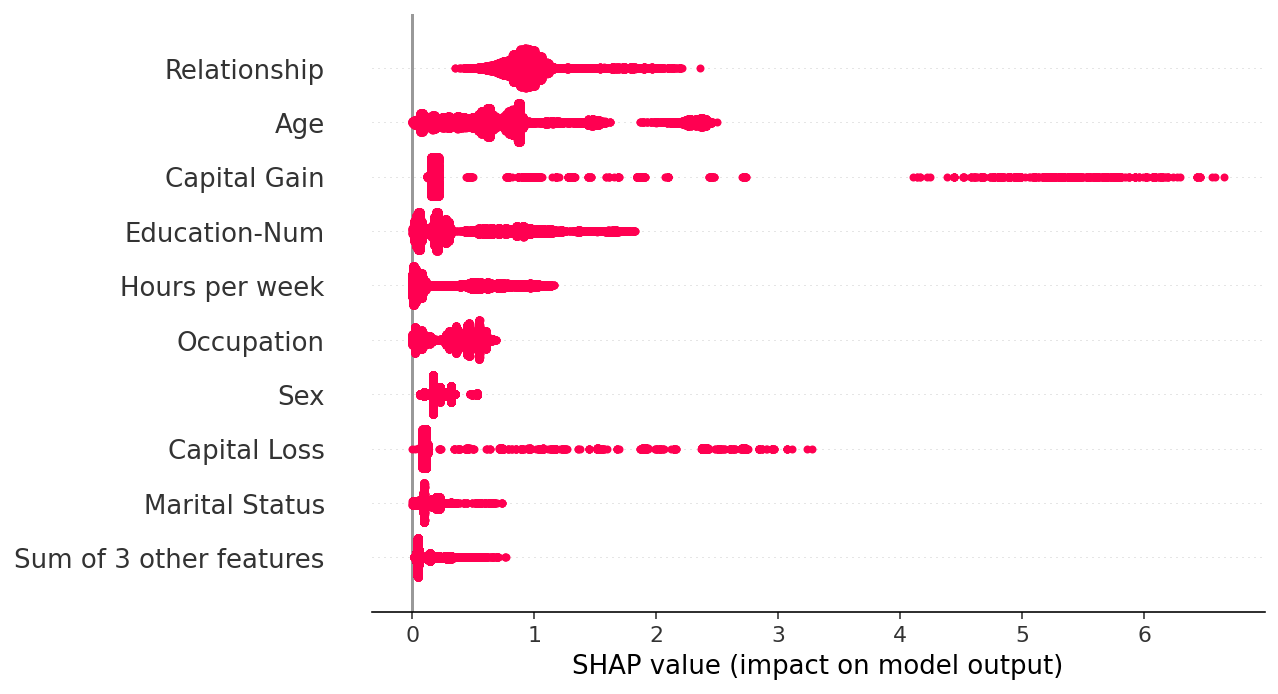
By taking the absolute value and using a solid color we get a compromise between the complexity of the bar plot and the full beeswarm plot. Note that the bar plots above are just summary statistics from the values shown in the beeswarm plots below.
[25]:
shap.plots.beeswarm(shap_values.abs, color="shap_red")
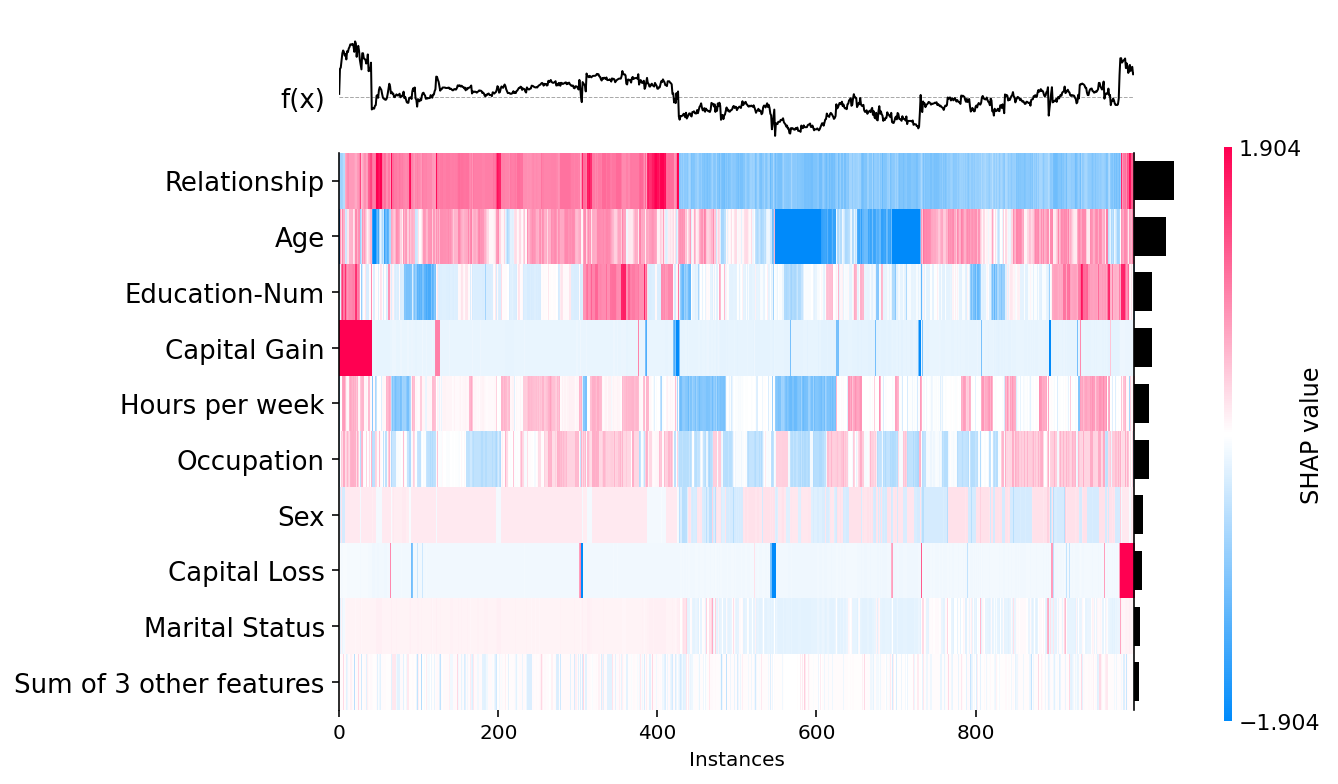
[26]:
shap.plots.heatmap(shap_values[:1000])
[27]:
shap.plots.scatter(shap_values[:, "Age"])
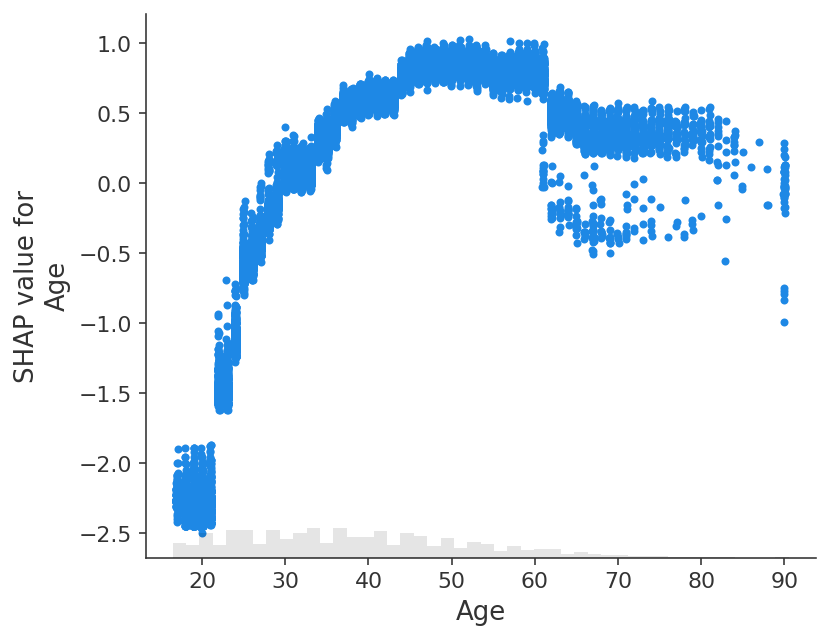
[28]:
shap.plots.scatter(shap_values[:, "Age"], color=shap_values)
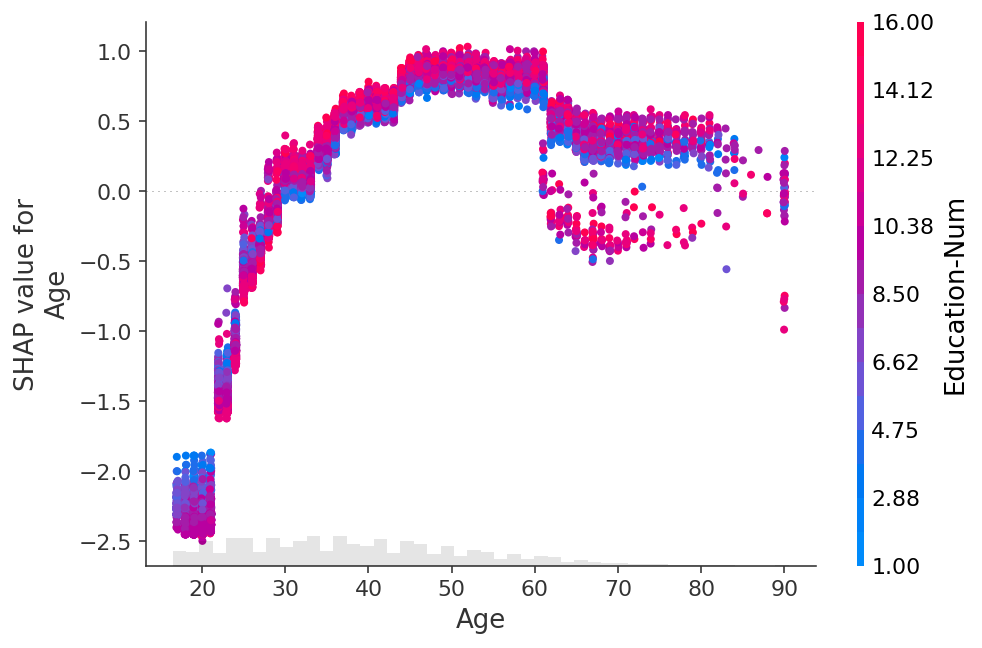
[29]:
shap.plots.scatter(shap_values[:, "Age"], color=shap_values[:, "Capital Gain"])
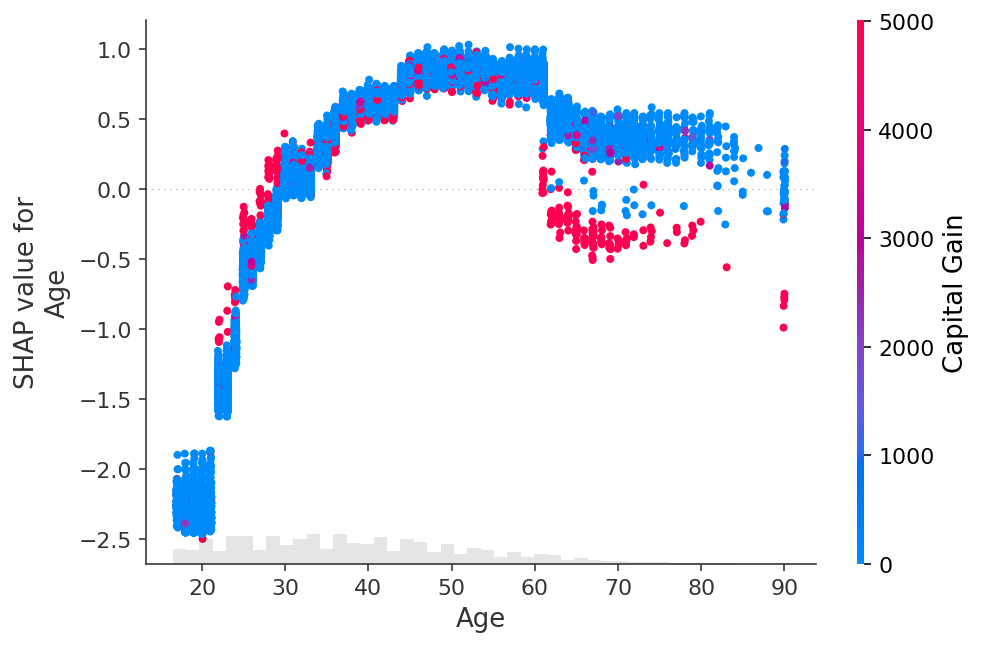
[30]:
shap.plots.scatter(shap_values[:, "Relationship"], color=shap_values)
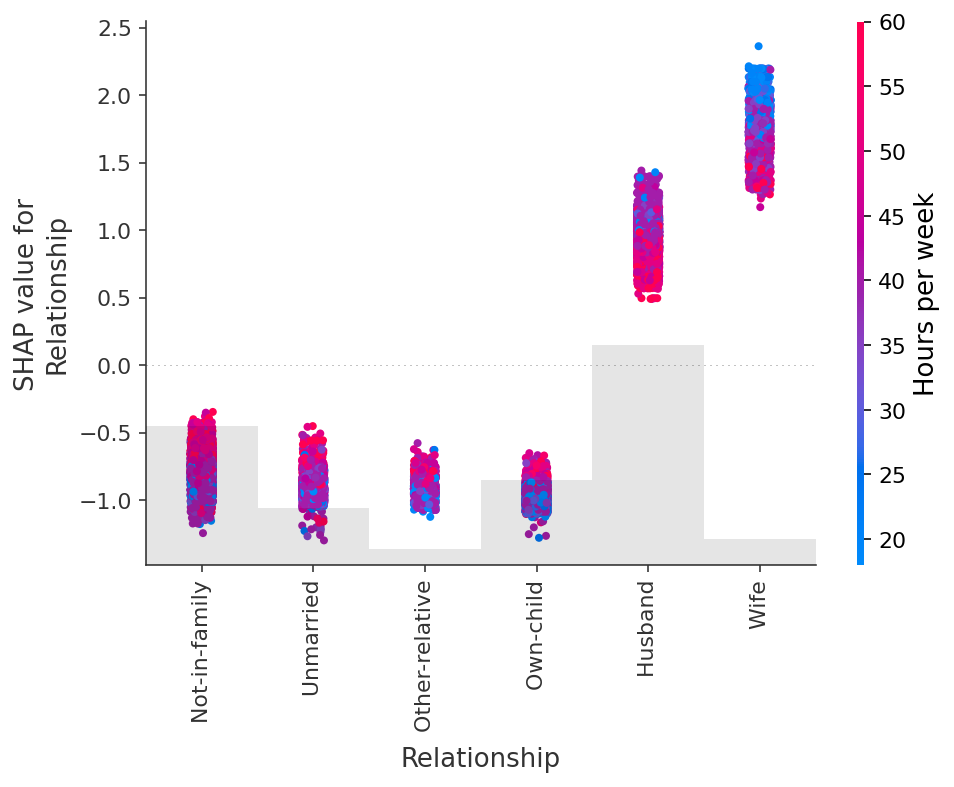
Dealing with correlated features
[31]:
clustering = shap.utils.hclust(X_adult, y_adult)
[32]:
shap.plots.bar(shap_values, clustering=clustering)
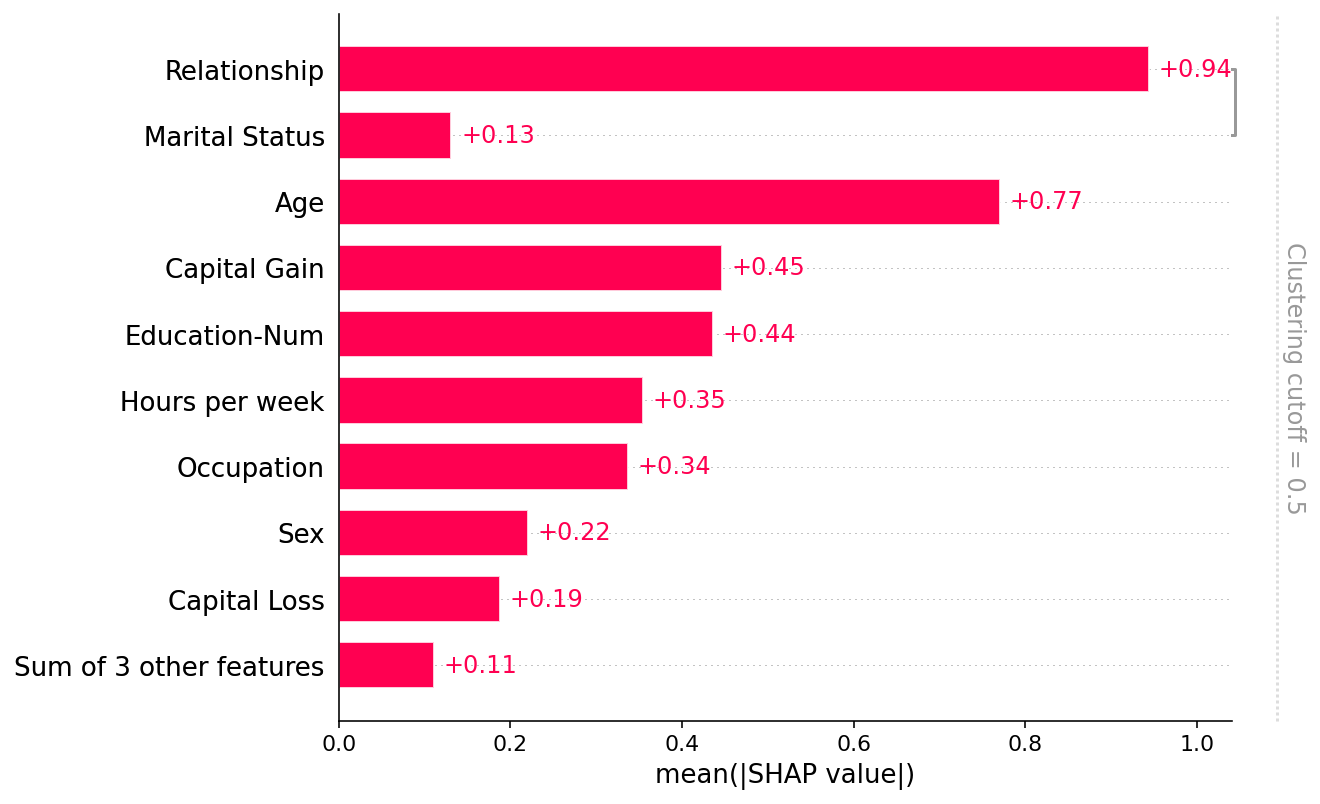
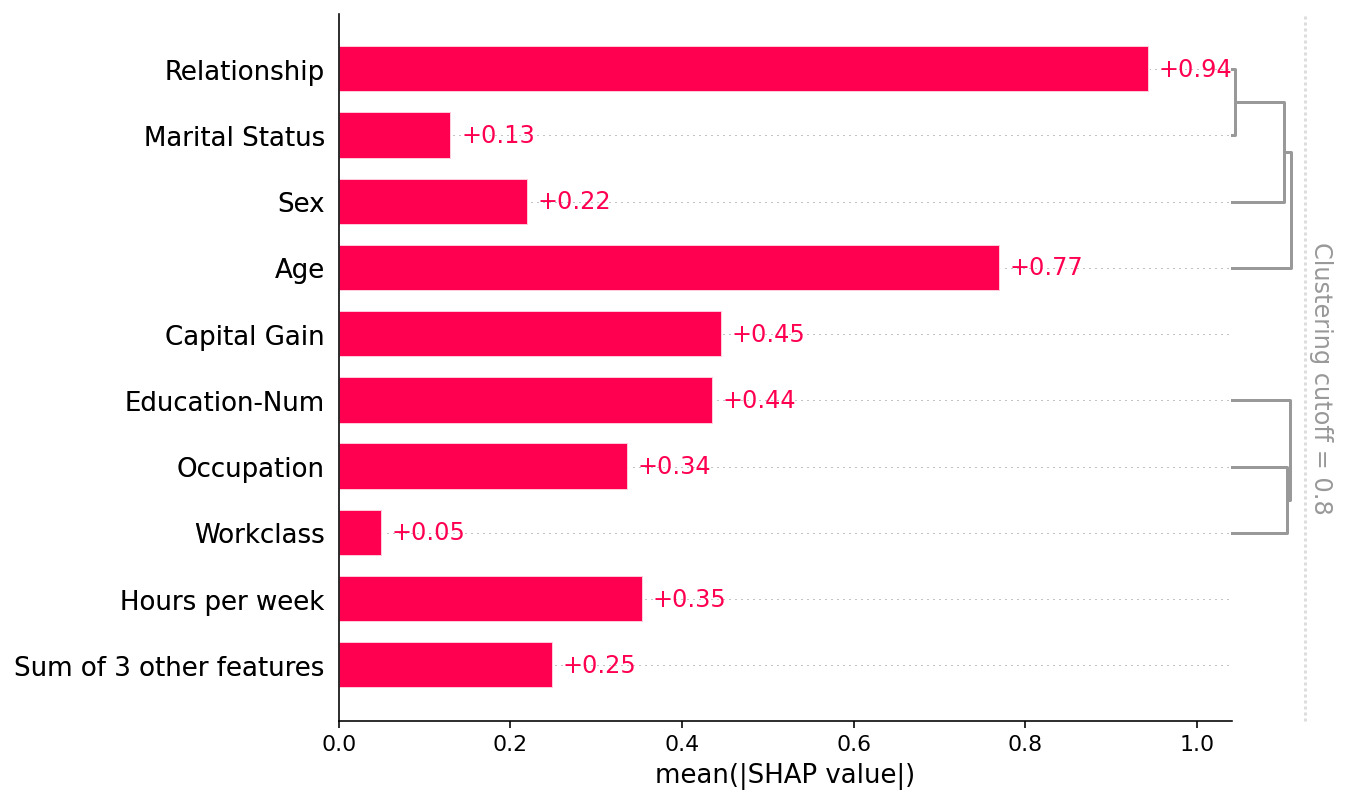
[33]:
shap.plots.bar(shap_values, clustering=clustering, clustering_cutoff=0.8)
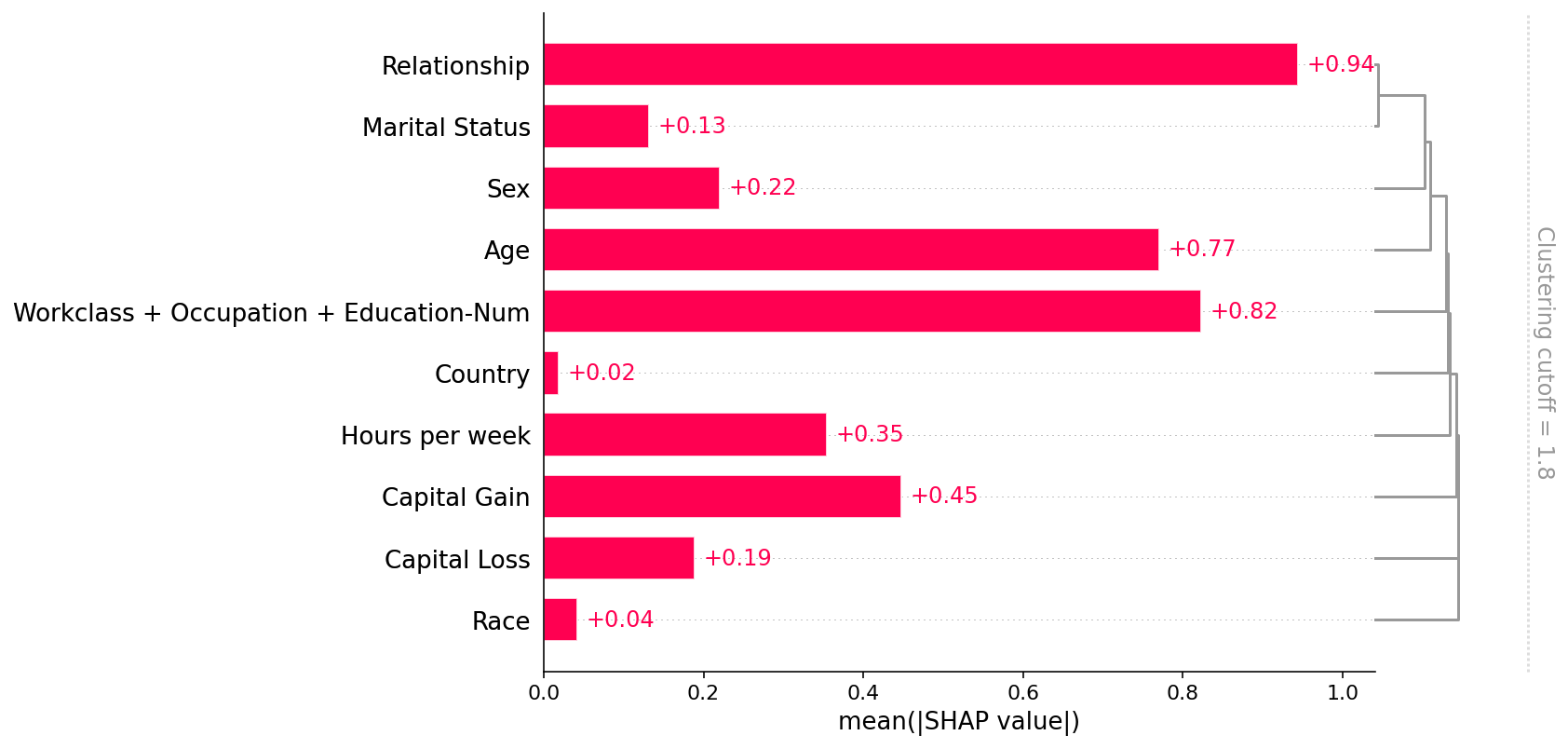
[34]:
shap.plots.bar(shap_values, clustering=clustering, clustering_cutoff=1.8)
Explaining a transformers NLP model
This demonstrates how SHAP can be applied to complex model types with highly structured inputs.
[35]:
import datasets
import numpy as np
import scipy as sp
import torch
import transformers
# load a BERT sentiment analysis model
tokenizer = transformers.DistilBertTokenizerFast.from_pretrained("distilbert-base-uncased")
model = transformers.DistilBertForSequenceClassification.from_pretrained(
"distilbert-base-uncased-finetuned-sst-2-english"
).cuda()
# define a prediction function
def f(x):
tv = torch.tensor([tokenizer.encode(v, padding="max_length", max_length=500, truncation=True) for v in x]).cuda()
outputs = model(tv)[0].detach().cpu().numpy()
scores = (np.exp(outputs).T / np.exp(outputs).sum(-1)).T
val = sp.special.logit(scores[:, 1]) # use one vs rest logit units
return val
# build an explainer using a token masker
explainer = shap.Explainer(f, tokenizer)
# explain the model's predictions on IMDB reviews
imdb_train = datasets.load_dataset("imdb")["train"]
shap_values = explainer(imdb_train[:10], fixed_context=1, batch_size=2)
2022-06-15 14:43:09.022292: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 AVX512F FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2022-06-15 14:43:09.731330: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1510] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 8395 MB memory: -> device: 0, name: NVIDIA GeForce RTX 2080 Ti, pci bus id: 0000:15:00.0, compute capability: 7.5
2022-06-15 14:43:09.732184: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1510] Created device /job:localhost/replica:0/task:0/device:GPU:1 with 9631 MB memory: -> device: 1, name: NVIDIA GeForce RTX 2080 Ti, pci bus id: 0000:21:00.0, compute capability: 7.5
Reusing dataset imdb (/home/slundberg/.cache/huggingface/datasets/imdb/plain_text/1.0.0/2fdd8b9bcadd6e7055e742a706876ba43f19faee861df134affd7a3f60fc38a1)
Partition explainer: 9it [00:25, 2.80s/it]Token indices sequence length is longer than the specified maximum sequence length for this model (720 > 512). Running this sequence through the model will result in indexing errors
Partition explainer: 11it [00:33, 4.21s/it]
[36]:
# plot a sentence's explanation
shap.plots.text(shap_values[2])
[37]:
shap.plots.bar(shap_values.abs.mean(0))
Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray
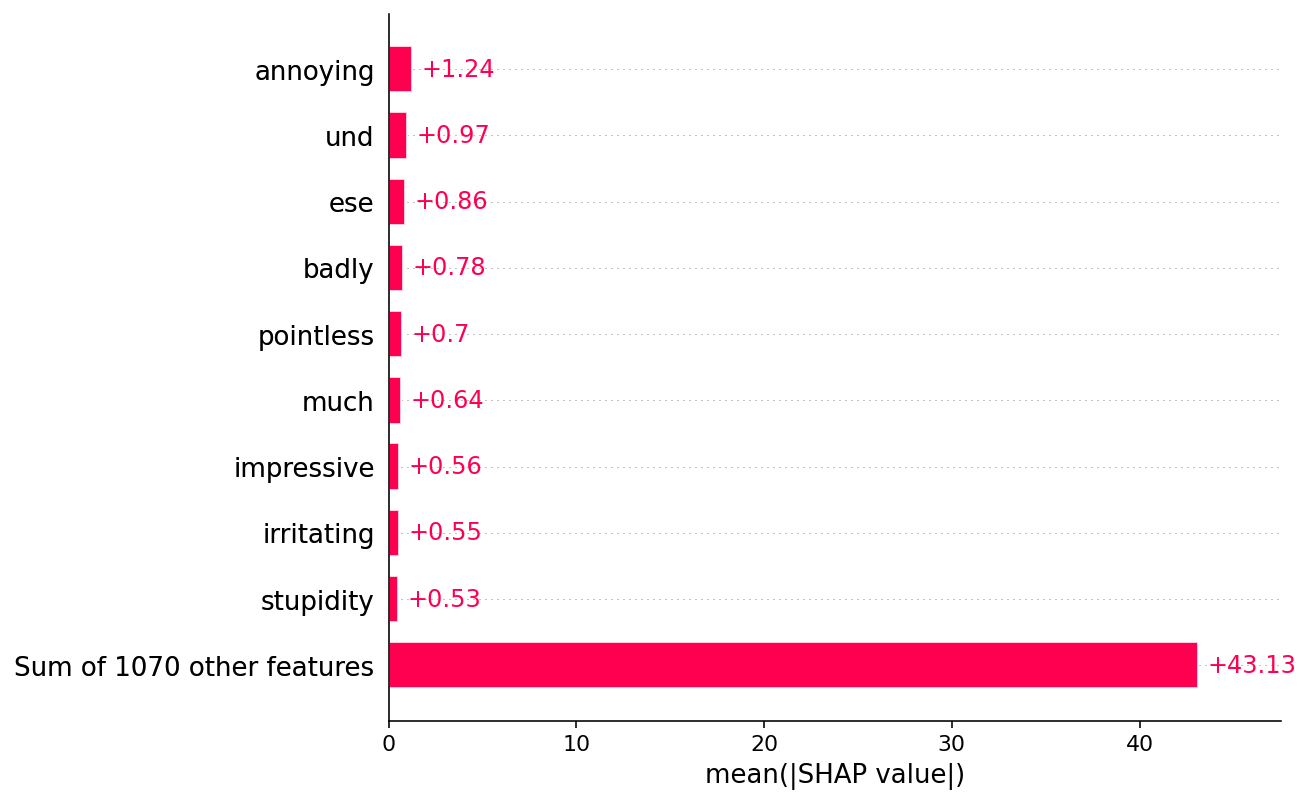
[38]:
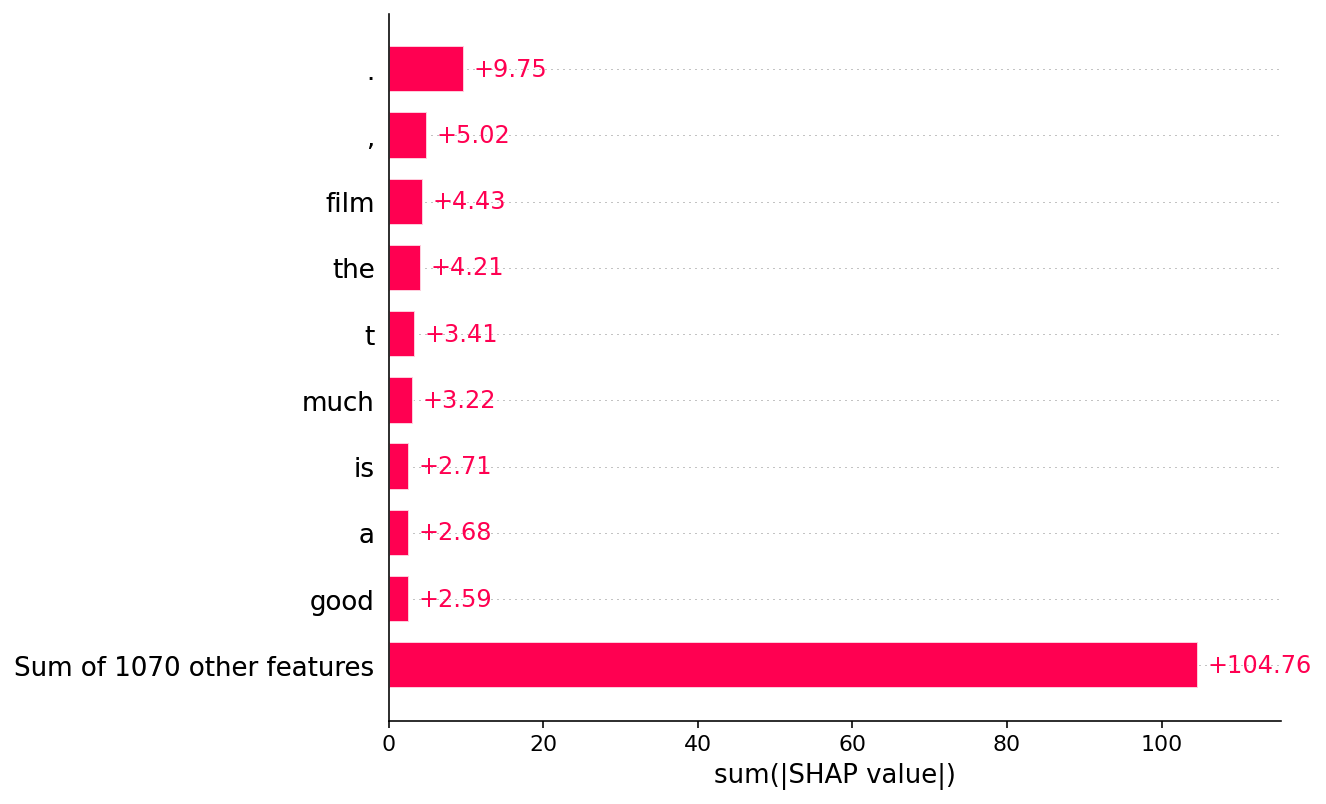
shap.plots.bar(shap_values.abs.sum(0))
Have an idea for more helpful examples? Pull requests that add to this documentation notebook are encouraged!