Explaining quantitative measures of fairness
This hands-on article connects explainable AI methods with fairness measures and shows how modern explainability methods can enhance the usefulness of quantitative fairness metrics. By using SHAP (a popular explainable AI tool) we can decompose measures of fairness and allocate responsibility for any observed disparity among each of the model’s input features. Explaining these quantitative fairness metrics can reduce the concerning tendency to rely on them as opaque standards of fairness, and instead promote their informed use as tools for understanding how model behavior differs between groups.
Quantitative fairness metrics seek to bring mathematical precision to the definition of fairness in machine learning [1]. Definitions of fairness however are deeply rooted in human ethical principles, and so on value judgements that often depend critically on the context in which a machine learning model is being used. This practical dependence on value judgements manifests itself in the mathematics of quantitative fairness measures as a set of trade-offs between sometimes mutually incompatible definitions of fairness [2]. Since fairness relies on context-dependent value judgements it is dangerous to treat quantitative fairness metrics as opaque black-box measures of fairness, since doing so may obscure important value judgment choices.
How SHAP can be used to explain various measures of model fairness
This article is not about how to choose the “correct” measure of model fairness, but rather about explaining whichever metric you have chosen. Which fairness metric is most appropriate depends on the specifics of your context, such as what laws apply, how the output of the machine learning model impacts people, and what value you place on various outcomes and hence tradeoffs. Here we will use the classic demographic parity metric, since it is simple and closely connected to the legal notion of disparate impact. The same analysis can also be applied to other metrics such as decision theory cost, equalized odds, equal opportunity, or equal quality of service. Demographic parity states that the output of the machine learning model should be equal between two or more groups. The demographic parity difference is then a measure of how much disparity there is between model outcomes in two groups of samples.
Since SHAP decomposes the model output into feature attributions with the same units as the original model output, we can first decompose the model output among each of the input features using SHAP, and then compute the demographic parity difference (or any other fairness metric) for each input feature seperately using the SHAP value for that feature. Because the SHAP values sum up to the model’s output, the sum of the demographic parity differences of the SHAP values also sum up to the demographic parity difference of the whole model.
What SHAP fairness explanations look like in various simulated scenarios
To help us explore the potential usefulness of explaining quantitative fairness metrics we consider a simple simulated scenario based on credit underwriting. In our simulation there are four underlying factors that drive the risk of default for a loan: income stability, income amount, spending restraint, and consistency. These underlying factors are not observed, but they variously influence four different observable features: job history, reported income, credit inquiries, and late payments. Using this simulation we generate random samples and then train a non-linear XGBoost classifier to predict the probability of default. The same process also works for any other model type supported by SHAP, just remember that explanations of more complicated models hide more of the model’s details.
By introducing sex-specific reporting errors into a fully specified simulation we can observe how the biases caused by these errors are captured by our chosen fairness metric. In our simulated case the true labels (will default on a loan) are statistically independent of sex (the sensitive class we use to check for fairness). So any disparity between men and women means one or both groups are being modeled incorrectly due to feature measurement errors, labeling errors, or model errors. If the true labels you are predicting (which might be different than the training labels you have access to) are not statistically independent of the sensitive feature you are considering, then even a perfect model with no errors would fail demographic parity. In these cases fairness explanations can help you determine which sources of demographic disparity are valid.
[1]:
# here we define a function that we can call to execute our simulation under
# a variety of different alternative scenarios
import numpy as np
import pandas as pd
import shap
%config InlineBackend.figure_format = 'retina'
def run_credit_experiment(
N,
job_history_sex_impact=0,
reported_income_sex_impact=0,
income_sex_impact=0,
late_payments_sex_impact=0,
default_rate_sex_impact=0,
include_brandx_purchase_score=False,
include_sex=False,
):
np.random.seed(0)
sex = np.random.randint(0, 2, N) == 1 # randomly half men and half women
# four hypothetical causal factors influence customer quality
# they are all scaled to the same units between 0-1
income_stability = np.random.rand(N)
income_amount = np.random.rand(N)
if income_sex_impact > 0:
income_amount -= income_sex_impact / 90000 * sex * np.random.rand(N)
income_amount -= income_amount.min()
income_amount /= income_amount.max()
spending_restraint = np.random.rand(N)
consistency = np.random.rand(N)
# intuitively this product says that high customer quality comes from simultaneously
# being strong in all factors
customer_quality = income_stability * income_amount * spending_restraint * consistency
# job history is a random function of the underlying income stability feature
job_history = np.maximum(
10 * income_stability + 2 * np.random.rand(N) - job_history_sex_impact * sex * np.random.rand(N),
0,
)
# reported income is a random function of the underlying income amount feature
reported_income = np.maximum(
10000
+ 90000 * income_amount
+ np.random.randn(N) * 10000
- reported_income_sex_impact * sex * np.random.rand(N),
0,
)
# credit inquiries is a random function of the underlying spending restraint and income amount features
credit_inquiries = np.round(6 * np.maximum(-spending_restraint + income_amount, 0)) + np.round(
np.random.rand(N) > 0.1
)
# credit inquiries is a random function of the underlying consistency and income stability features
late_payments = np.maximum(
np.round(3 * np.maximum((1 - consistency) + 0.2 * (1 - income_stability), 0))
+ np.round(np.random.rand(N) > 0.1)
- np.round(late_payments_sex_impact * sex * np.random.rand(N)),
0,
)
# bundle everything into a data frame and define the labels based on the default rate and customer quality
X = pd.DataFrame(
{
"Job history": job_history,
"Reported income": reported_income,
"Credit inquiries": credit_inquiries,
"Late payments": late_payments,
}
)
default_rate = 0.40 + sex * default_rate_sex_impact
y = customer_quality < np.percentile(customer_quality, default_rate * 100)
if include_brandx_purchase_score:
brandx_purchase_score = sex + 0.8 * np.random.randn(N)
X["Brand X purchase score"] = brandx_purchase_score
if include_sex:
X["Sex"] = sex + 0
# build model
import xgboost
model = xgboost.XGBClassifier(max_depth=1, n_estimators=500, subsample=0.5, learning_rate=0.05)
model.fit(X, y)
# build explanation
import shap
explainer = shap.TreeExplainer(model, shap.sample(X, 100))
shap_values = explainer.shap_values(X)
return shap_values, sex, X, explainer.expected_value
Scenario A: No reporting errors
Our first experiment is a simple baseline check where we refrain from introducing any sex-specific reporting errors. While we could use any model output to measure demographic parity, we use the continuous log-odds score from a binary XGBoost classifier. As expected, this baseline experiment results in no significant demographic parity difference between the credit scores of men and women. We can see this by plotting the difference between the average credit score for women and men as a bar plot and noting that zero is close to the margin of error (note that negative values mean women have a lower average predicted risk than men, and positive values mean that women have a higher average predicted risk than men):
[2]:
N = 10000
shap_values_A, sex_A, X_A, ev_A = run_credit_experiment(N)
model_outputs_A = ev_A + shap_values_A.sum(1)
glabel = "Demographic parity difference\nof model output for women vs. men"
xmin = -0.8
xmax = 0.8
shap.group_difference_plot(shap_values_A.sum(1), sex_A, xmin=xmin, xmax=xmax, xlabel=glabel)
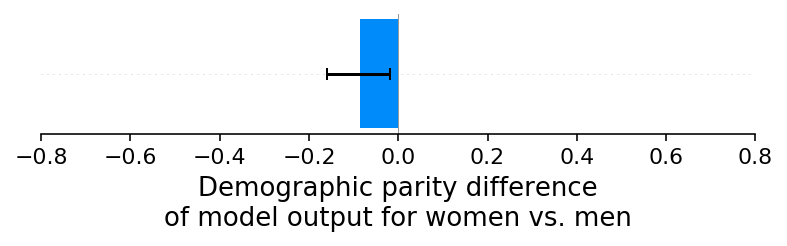
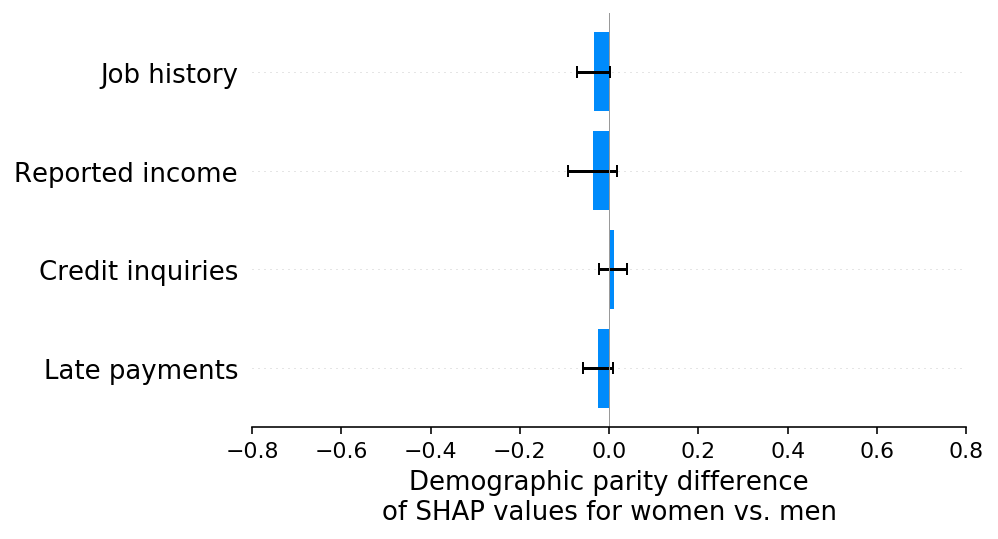
Now we can use SHAP to decompose the model output among each of the model’s input features and then compute the demographic parity difference on the component attributed to each feature. As noted above, because the SHAP values sum up to the model’s output, the sum of the demographic parity differences of the SHAP values for each feature sum up to the demographic parity difference of the whole model. This means that the sum of the bars below equals the bar above (the demographic parity difference of our baseline scenario model).
[3]:
slabel = "Demographic parity difference\nof SHAP values for women vs. men"
shap.group_difference_plot(shap_values_A, sex_A, X_A.columns, xmin=xmin, xmax=xmax, xlabel=slabel)
Scenario B: An under-reporting bias for women’s income
In our baseline scenario we designed a simulation where sex had no impact on any of the features or labels used by the model. Here in scenario B we introduce an under-reporting bias for women’s income into the simulation. The point here is not how realistic it would be for women’s income to be under-reported in the real-world, but rather how we can identify that a sex-specific bias has been introduced and understand where it came from. By plotting the difference in average model output (default risk) between women and men we can see that the income under-reporting bias has created a significant demographic parity difference where women now have a higher risk of default than men:
[4]:
shap_values_B, sex_B, X_B, ev_B = run_credit_experiment(N, reported_income_sex_impact=30000)
model_outputs_B = ev_B + shap_values_B.sum(1)
shap.group_difference_plot(shap_values_B.sum(1), sex_B, xmin=xmin, xmax=xmax, xlabel=glabel)
95%|=================== | 9542/10000 [00:11<00:00]

If this were a real application, this demographic parity difference might trigger an in-depth analysis of the model to determine what might be causing the disparity. While this investigation is challenging given just a single demographic parity difference value, it is much easier given the per-feature demographic parity decomposition based on SHAP. Using SHAP we can see there is a significant bias coming from the reported income feature that is increasing the risk of women disproportionately to men. This allows us to quickly identify which feature has the reporting bias that is causing our model to violate demographic parity:
[5]:
shap.group_difference_plot(shap_values_B, sex_B, X_B.columns, xmin=xmin, xmax=xmax, xlabel=slabel)
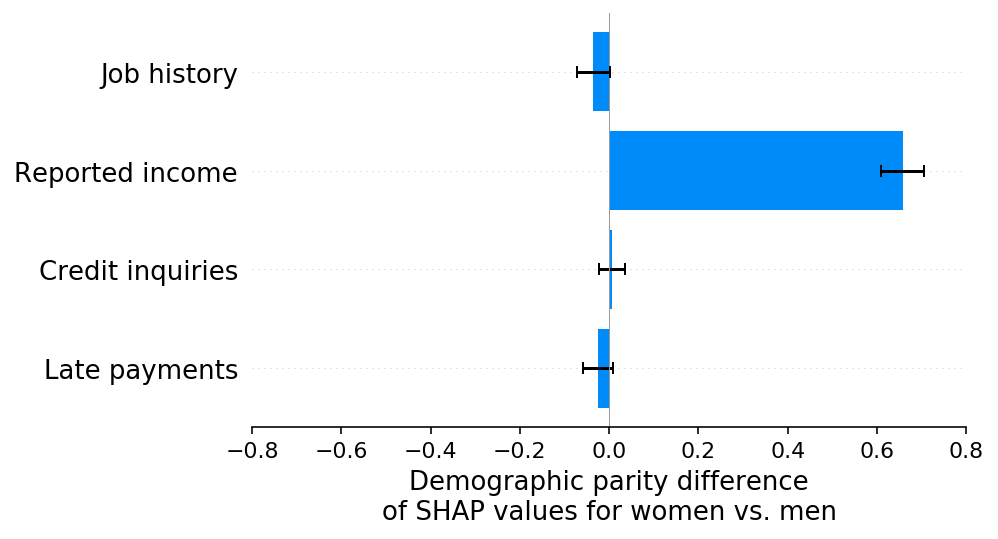
It is important to note at this point how our assumptions can impact the interpretation of SHAP fairness explanations. In our simulated scenario we know that women actually have identical income profiles to men, so when we see that the reported income feature is biased lower for women than for men, we know that has come from a bias in the measurement errors in the reported income feature. The best way to address this problem would be figure out how to debias the measurement errors in the reported income feature. Doing so would create a more accurate model that also has less demographic disparity. However, if we instead assume that women actually are making less money than men (and it is not just a reporting error), then we can’t just “fix” the reported income feature. Instead we have to carefully consider how best to account for real differences in default risk between two protected groups. It is impossible to determine which of these two situations is happening using just the SHAP fairness explanation, since in both cases the reported income feature will be responsible for an observed disparity between the predicted risks of men and women.
Scenario C: An under-reporting bias for women’s late payments
To verify that SHAP demographic parity explanations can correctly detect disparities regardless of the direction of effect or source feature, we repeat our previous experiment but instead of an under-reporting bias for income, we introduce an under-reporting bias for women’s late payment rates. This results in a significant demographic parity difference for the model’s output where now women have a lower average default risk than men:
[6]:
shap_values_C, sex_C, X_C, ev_C = run_credit_experiment(N, late_payments_sex_impact=2)
model_outputs_C = ev_C + shap_values_C.sum(1)
shap.group_difference_plot(shap_values_C.sum(1), sex_C, xmin=xmin, xmax=xmax, xlabel=glabel)

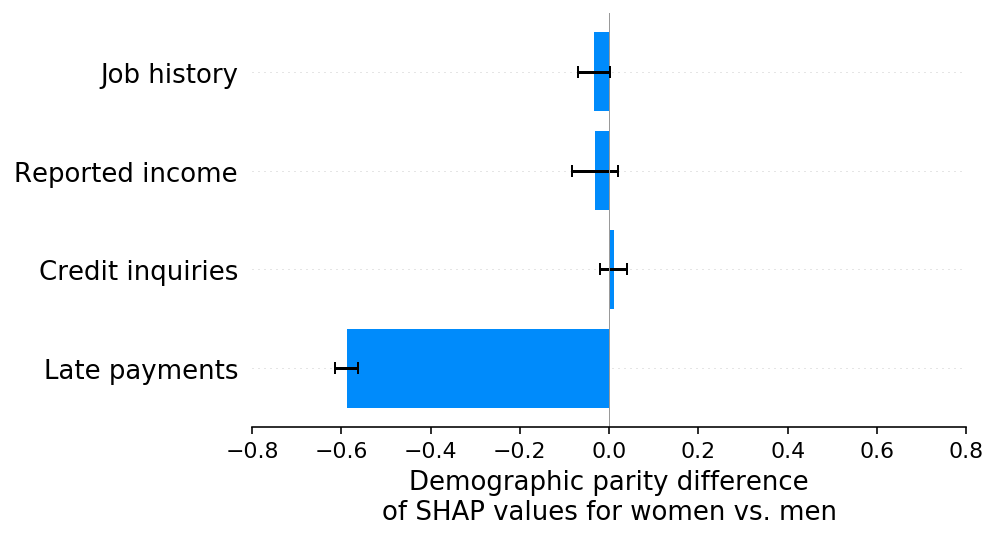
And as we would hope, the SHAP explanations correctly highlight the late payments feature as the cause of the model’s demographic parity difference, as well as the direction of the effect:
[7]:
shap.group_difference_plot(shap_values_C, sex_C, X_C.columns, xmin=xmin, xmax=xmax, xlabel=slabel)
Scenario D: An under-reporting bias for women’s default rates
The experiments above focused on introducing reporting errors for specific input features. Next we consider what happens when we introduce reporting errors on the training labels through an under-reporting bias on women’s default rates (which means defaults are less likely to be reported for women than men). Interestingly, for our simulated scenario this results in no significant demographic parity differences in the model’s output:
[8]:
shap_values_D, sex_D, X_D, ev_D = run_credit_experiment(N, default_rate_sex_impact=-0.1) # 20% change
model_outputs_D = ev_D + shap_values_D.sum(1)
shap.group_difference_plot(shap_values_D.sum(1), sex_D, xmin=xmin, xmax=xmax, xlabel=glabel)
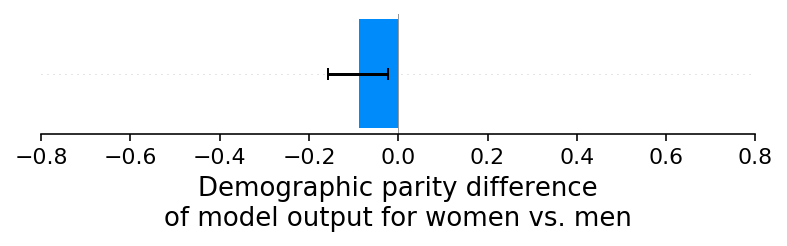
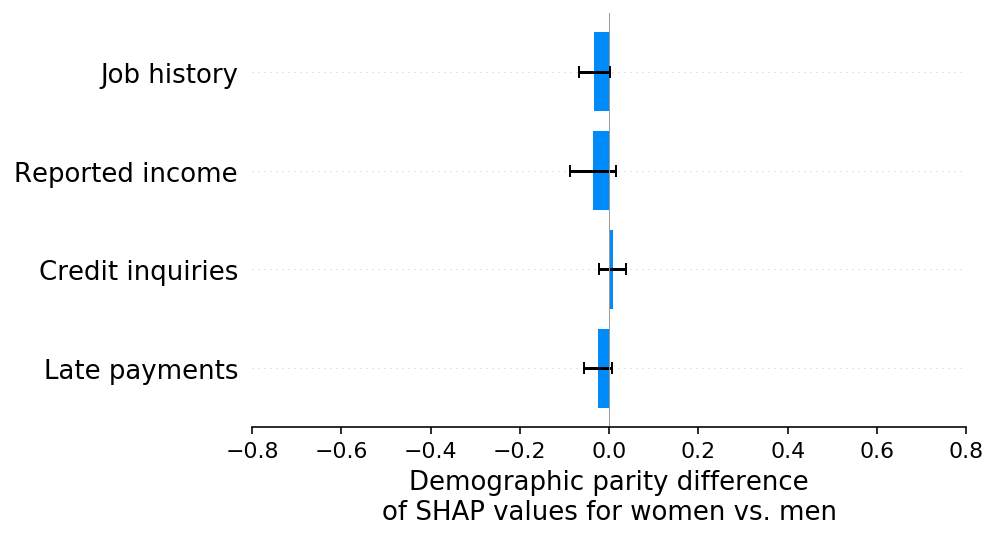
We also see no evidence of any demographic parity differences in the SHAP explanations:
[9]:
shap.group_difference_plot(shap_values_D, sex_D, X_D.columns, xmin=xmin, xmax=xmax, xlabel=slabel)
Scenario E: An under-reporting bias for women’s default rates, take 2
It may at first be surprising that no demographic parity differences were caused when we introduced an under-reporting bias on women’s default rates. This is because none of the four features in our simulation are significantly correlated with sex, so none of them could be effectively used to model the bias we introduced into the training labels. If we now instead provide a new feature (brand X purchase score) to the model that is correlated with sex, then we see a demographic parity difference emerge as that feature is used by the model to capture the sex-specific bias in the training labels:
[10]:
shap_values_E, sex_E, X_E, ev_E = run_credit_experiment(
N, default_rate_sex_impact=-0.1, include_brandx_purchase_score=True
)
model_outputs_E = ev_E + shap_values_E.sum(1)
shap.group_difference_plot(shap_values_E.sum(1), sex_E, xmin=xmin, xmax=xmax, xlabel=glabel)
98%|===================| 9794/10000 [00:11<00:00]
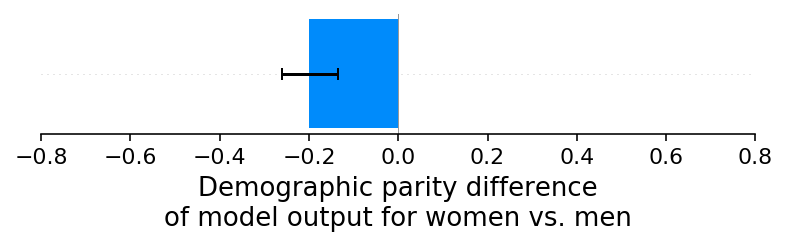
When we explain the demographic parity difference with SHAP we see that, as expected, the brand X purchase score feature drives the difference. In this case it is not because we have a bias in how we measure the brand X purchase score feature, but rather because we have a bias in our training label that gets captured by any input features that are sufficiently correlated with sex:
[11]:
shap.group_difference_plot(shap_values_E, sex_E, X_E.columns, xmin=xmin, xmax=xmax, xlabel=slabel)
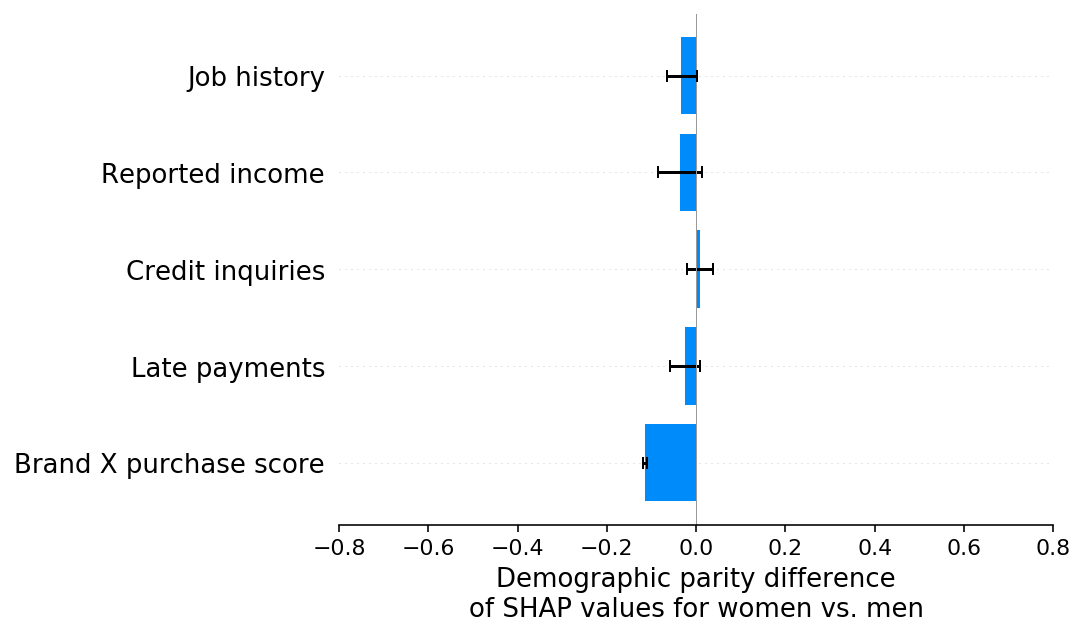
Scenario F: Teasing apart multiple under-reporting biases
When there is a single cause of reporting bias then both the classic demographic parity test on the model’s output, and the SHAP explanation of the demographic parity test capture the same bias effect (though the SHAP explanation can often have more statistical significance since it isolates the feature causing the bias). But what happens when there are multiple causes of bias occurring in a dataset? In this experiment we introduce two such biases, an under-reporting of women’s default rates, and an under-reporting of women’s job history. These biases tend to offset each other in the global average and so a demographic parity test on the model’s output shows no measurable disparity:
[12]:
shap_values_F, sex_F, X_F, ev_F = run_credit_experiment(
N,
default_rate_sex_impact=-0.1,
include_brandx_purchase_score=True,
job_history_sex_impact=2,
)
model_outputs_F = ev_F + shap_values_F.sum(1)
shap.group_difference_plot(shap_values_F.sum(1), sex_F, xmin=xmin, xmax=xmax, xlabel=glabel)
100%|===================| 9996/10000 [00:11<00:00]
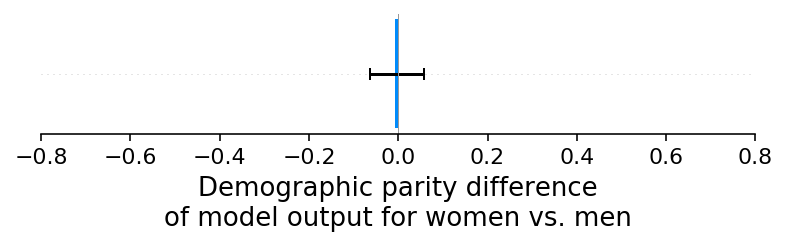
However, if we look at the SHAP explanation of the demographic parity difference we clearly see both (counteracting) biases:
[13]:
shap.group_difference_plot(shap_values_F, sex_F, X_F.columns, xmin=xmin, xmax=xmax, xlabel=slabel)
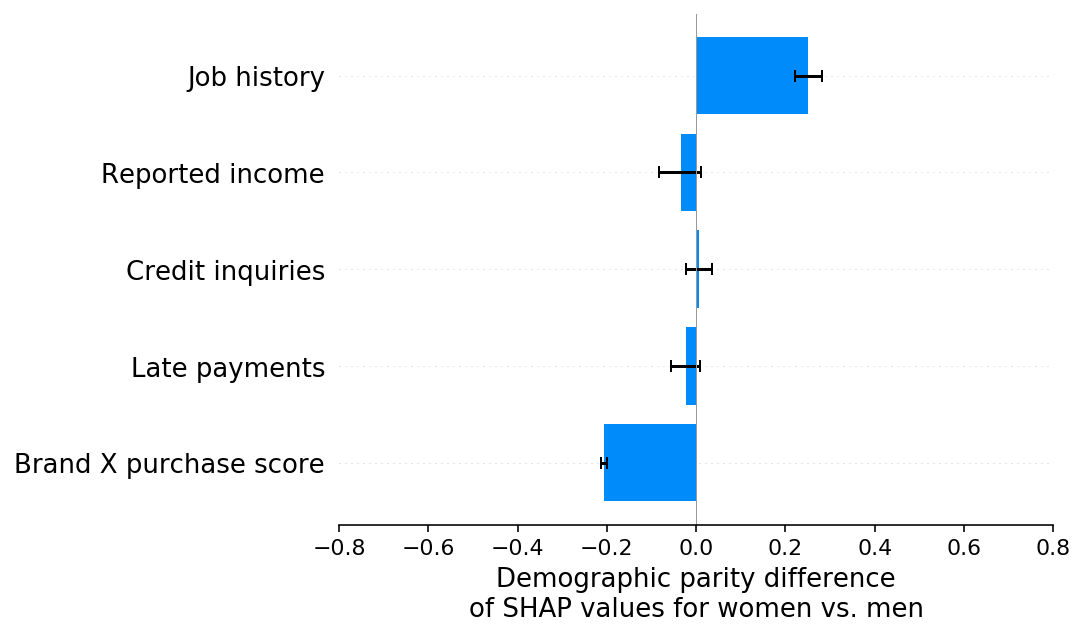
Identifying multiple potentially offsetting bias effects can be important since while on average there is no disparate impact on men or women, there is disparate impact on individuals. For example, in this simulation women who have not shopped at brand X will receive a lower credit score than they should have because of the bias present in job history reporting.
How introducing a protected feature can help distinguish between label bias and feature bias
In scenario F we were able to pick apart two distict forms of bias, one coming from job history under-reporting and one coming from default rate under-reporting. However, the bias from default rate under-reporting was not attributed to the default rate label, but rather to the brand X purchase score feature that happened to be correlated with sex. This still leaves us with some uncertainty about the true sources of demographic parity differences, since any difference attributed to an input feature could be due to an issue with that feature, or due to an issue with the training labels.
It turns out that in this case we can help disentangle label bias from feature bias by introducing sex as a variable directly into the model. The goal of introducing sex as an input feature is to cause the label bias to fall entirely on the sex feature, leaving the feature biases untouched. So we can then distinguish between label biases and feature biases by comparing the results of scenario F above to our new scenario G below. This of course creates an even stronger demographic parity difference than we had before, but that is fine since our goal here is not bias mitigation, but rather bias understanding.
[14]:
shap_values_G, sex_G, X_G, ev_G = run_credit_experiment(
N,
default_rate_sex_impact=-0.1,
include_brandx_purchase_score=True,
job_history_sex_impact=2,
include_sex=True,
)
model_outputs_G = ev_G + shap_values_G.sum(1)
shap.group_difference_plot(shap_values_G.sum(1), sex_G, xmin=xmin, xmax=xmax, xlabel=glabel)
97%|=================== | 9720/10000 [00:11<00:00]

The SHAP explanation for scenario G shows that all of the demographic parity difference that used to be attached to the brand X purchase score feature in scenario F has now moved to the sex feature, while none of the demographic parity difference attached to the job history feature in scenario F has moved. This can be interpreted to mean that all of the disparity attributed to brand X purchase score in scenario F was due to label bias, while all of the disparity attributed to job history in scenario F was due to feature bias.
[15]:
shap.group_difference_plot(shap_values_G, sex_G, X_G.columns, xmin=xmin, xmax=xmax, xlabel=slabel)
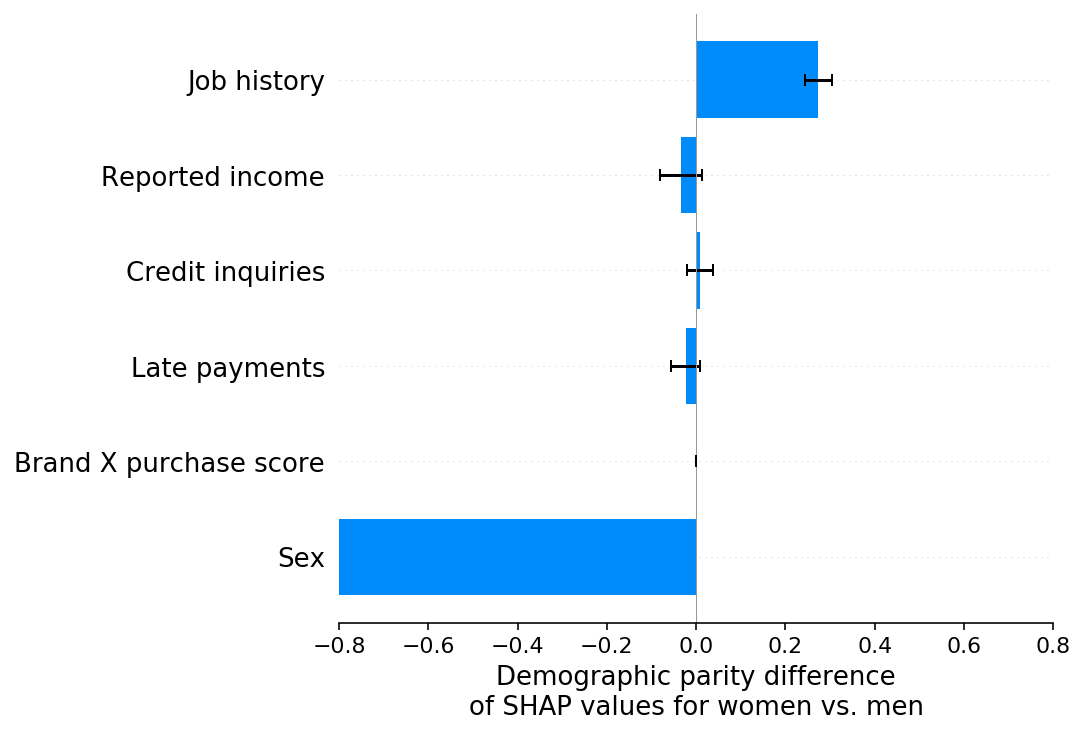
Conclusion
Fairness is a complex topic where clean mathematical answers almost always come with caveats and depend on ethical value judgements. This means that it is particularly important to not just use fairness metrics as black-boxes, but rather seek to understand how these metrics are computed and what aspects of your model and training data are impacting any disparities you observe. Decomposing quantitative fairness metrics using SHAP can reduce their opacity when the metrics are driven by measurement biases effecting only a few features. I hope you find the fairness explanations we demonstrated here help you better wrestle with the underlying value judgements inherent in fairness evaluation, and so help reduce the risk of unintended consequences that comes when we use fairness metrics in real world contexts.