Welcome to the SHAP documentation
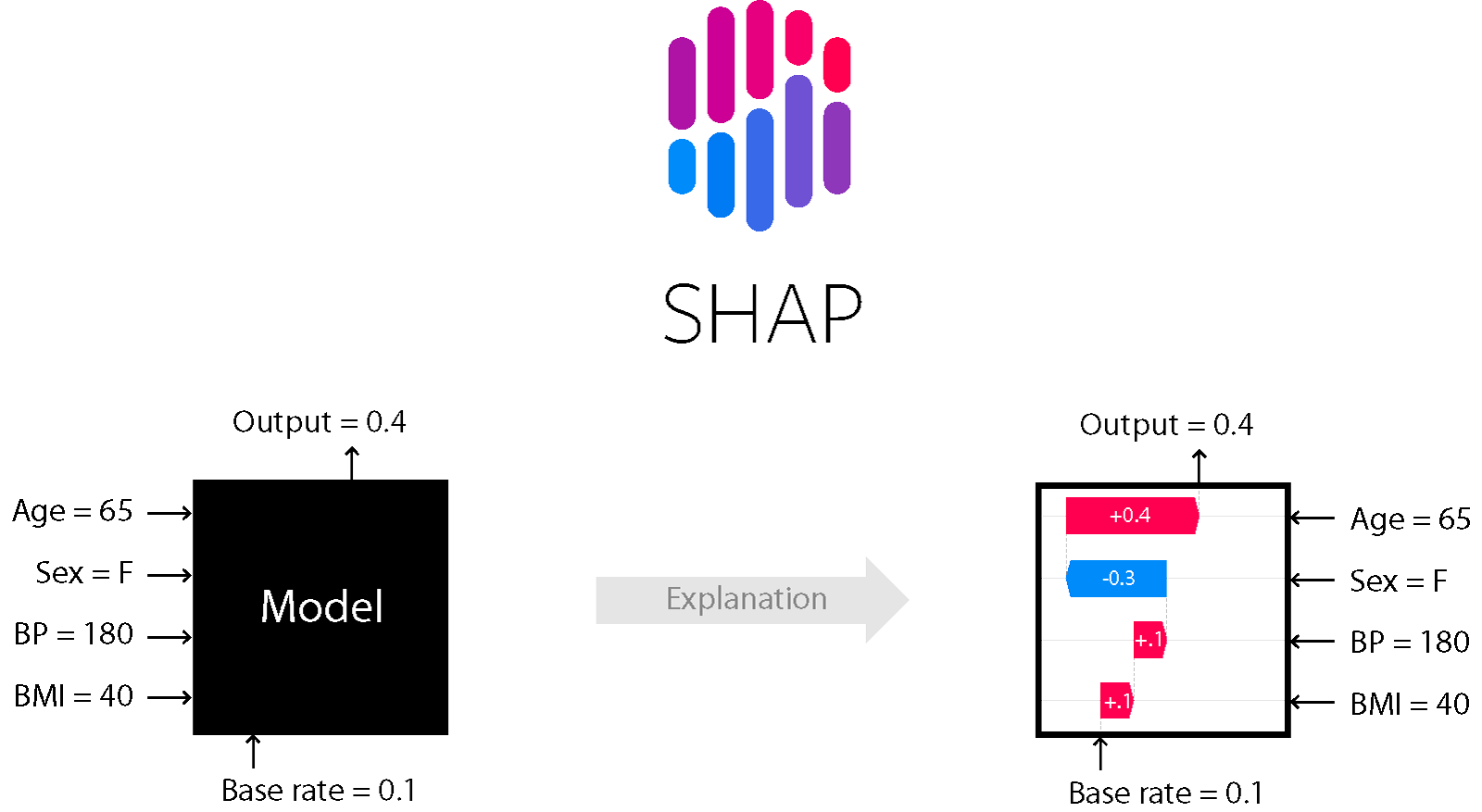
SHAP (SHapley Additive exPlanations) is a game theoretic approach to explain the output of any machine learning model. It connects optimal credit allocation with local explanations using the classic Shapley values from game theory and their related extensions (see papers for details and citations).
Install
SHAP can be installed from either PyPI or conda-forge:
pip install shap
or
conda install -c conda-forge shap
Introduction
Reference
Development