Census income classification with scikit-learn
This example uses the standard adult census income dataset from the UCI machine learning data repository. We train a k-nearest neighbors classifier using sci-kit learn and then explain the predictions.
[1]:
import sklearn
import shap
Load the census data
[2]:
X, y = shap.datasets.adult()
X["Occupation"] *= 1000 # to show the impact of feature scale on KNN predictions
X_display, y_display = shap.datasets.adult(display=True)
X_train, X_valid, y_train, y_valid = sklearn.model_selection.train_test_split(X, y, test_size=0.2, random_state=7)
Train a k-nearest neighbors classifier
Here we just train directly on the data, without any normalizations.
[4]:
knn = sklearn.neighbors.KNeighborsClassifier()
knn.fit(X_train, y_train)
[4]:
KNeighborsClassifier()
Explain predictions
Normally we would use a logit link function to allow the additive feature inputs to better map to the model’s probabilistic output space, but knn’s can produce infinite log odds ratios so we don’t for this example.
It is important to note that Occupation is the dominant feature in the 1000 predictions we explain. This is because it has larger variations in value than the other features and so it impacts the k-nearest neighbors calculations more.
[5]:
def f(x):
return knn.predict_proba(x)[:, 1]
med = X_train.median().values.reshape((1, X_train.shape[1]))
explainer = shap.Explainer(f, med)
shap_values = explainer(X_valid.iloc[0:1000, :])
Permutation explainer: 1001it [00:25, 38.69it/s]
[5]:
shap.plots.waterfall(shap_values[0])
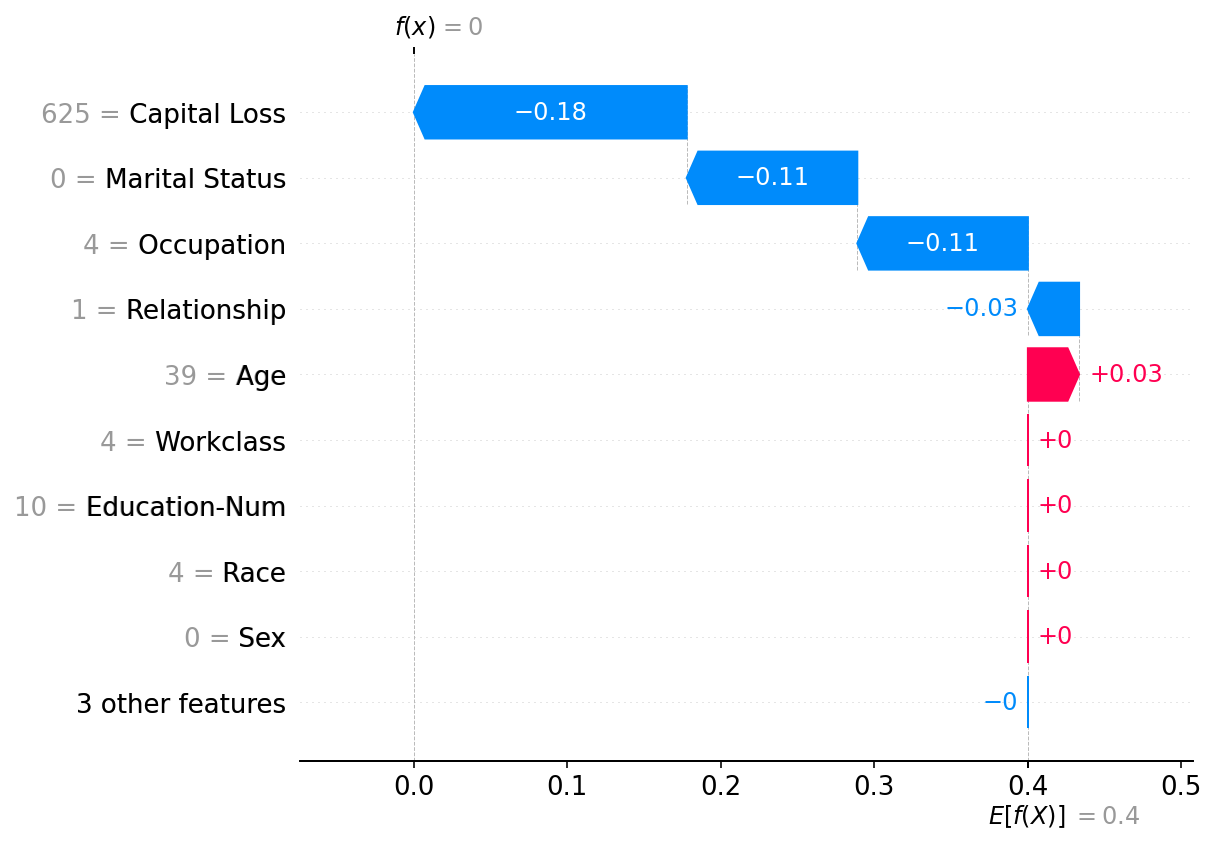
A summary beeswarm plot is an even better way to see the relative impact of all features over the entire dataset. Features are sorted by the sum of their SHAP value magnitudes across all samples.
[7]:
shap.plots.beeswarm(shap_values)
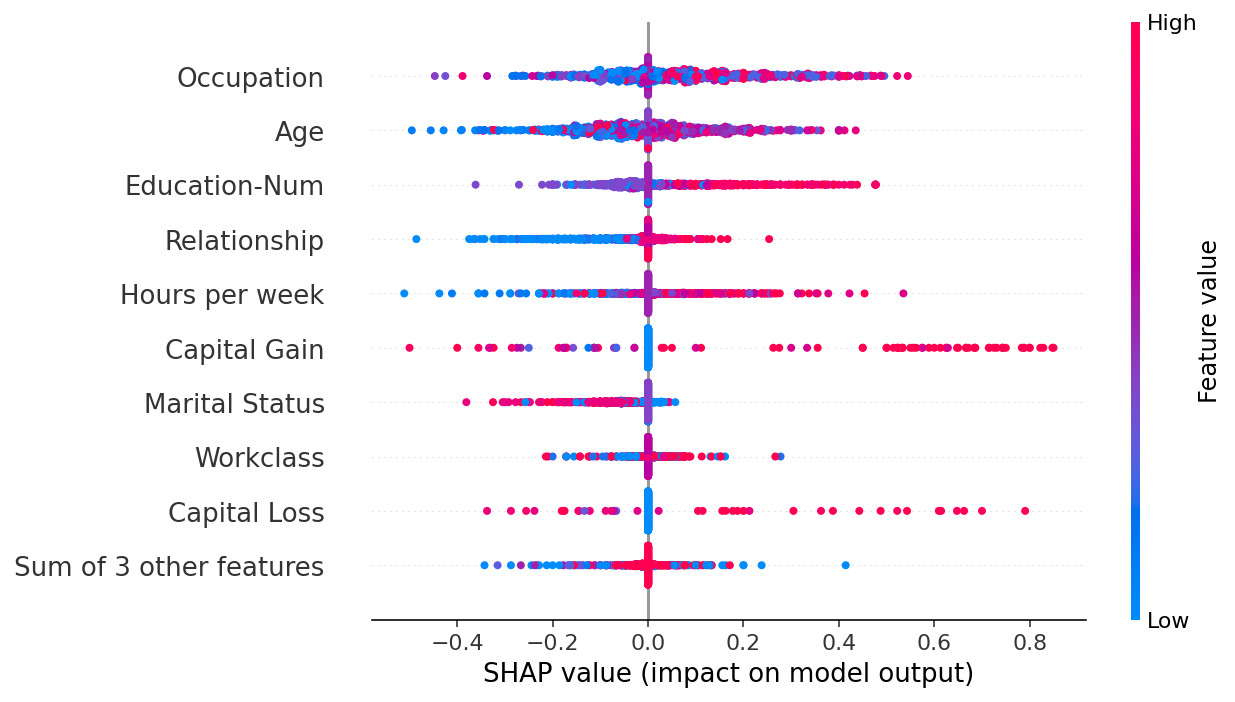
A heatmap plot provides another global view of the model’s behavior, this time with a focus on population subgroups.
[8]:
shap.plots.heatmap(shap_values)
Normalize the data before training the model
Here we retrain a KNN model on standardized data.
[9]:
# normalize data
dtypes = list(zip(X.dtypes.index, map(str, X.dtypes)))
X_train_norm = X_train.copy()
X_valid_norm = X_valid.copy()
for k, dtype in dtypes:
m = X_train[k].mean()
s = X_train[k].std()
X_train_norm[k] -= m
X_train_norm[k] /= s
X_valid_norm[k] -= m
X_valid_norm[k] /= s
[10]:
knn_norm = sklearn.neighbors.KNeighborsClassifier()
knn_norm.fit(X_train_norm, y_train)
[10]:
KNeighborsClassifier()
Explain predictions
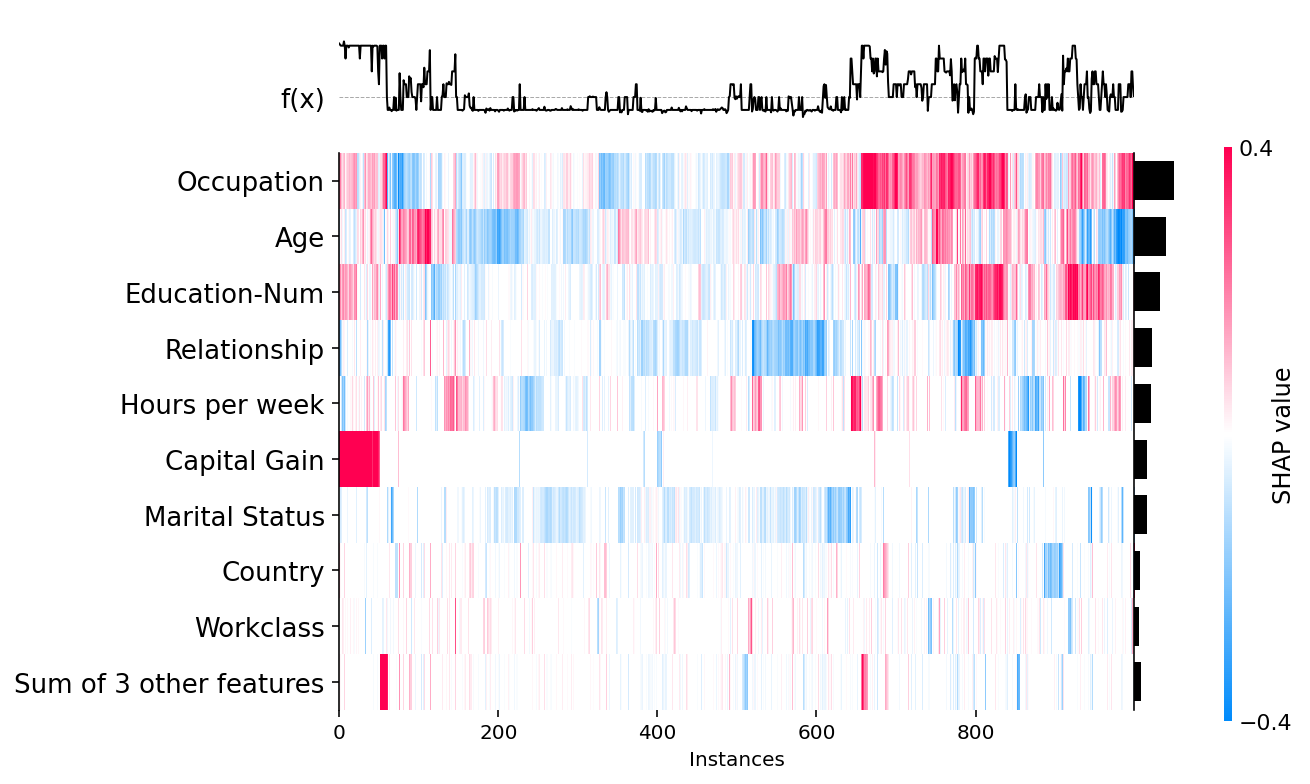
When we explain predictions from the new KNN model we find that Occupation is no longer the dominate feature, but instead more predictive features, such as marital status, drive most predictions. This is simple example of how explaining why your model is making it’s predicitons can uncover problems in the training process.
[11]:
def f(x):
return knn_norm.predict_proba(x)[:, 1]
med = X_train_norm.median().values.reshape((1, X_train_norm.shape[1]))
explainer = shap.Explainer(f, med)
shap_values_norm = explainer(X_valid_norm.iloc[0:1000, :])
Permutation explainer: 1001it [01:26, 11.55it/s]
With a summary plot with see marital status is the most important on average, but other features (such as captial gain) can have more impact on a particular individual.
[12]:
shap.summary_plot(shap_values_norm, X_valid.iloc[0:1000, :])
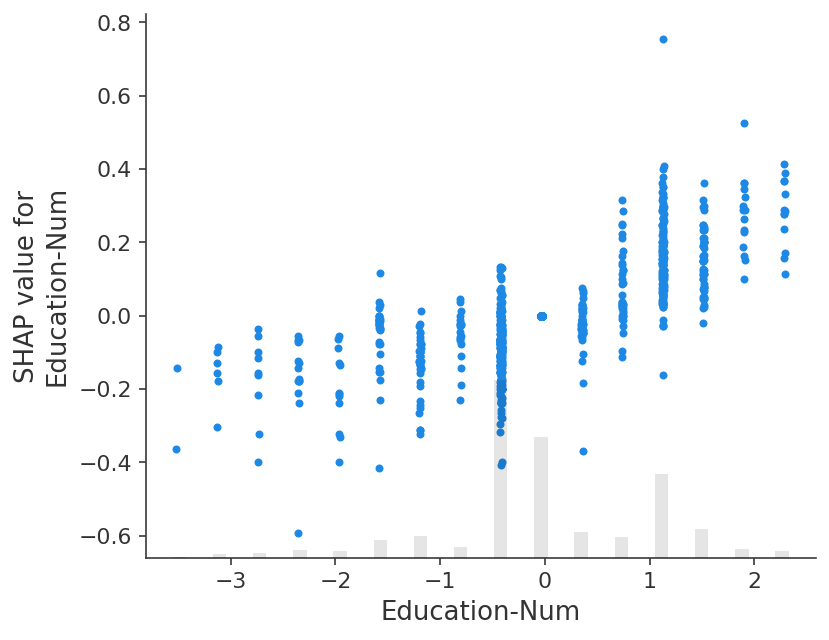
A dependence scatter plot shows how the number of years of education increases the chance of making over 50K annually.
[14]:
shap.plots.scatter(shap_values_norm[:, "Education-Num"])
Have an idea for more helpful examples? Pull requests that add to this documentation notebook are encouraged!